The End of Data Warehouses? Enter the Age of Dynamic Context Engines
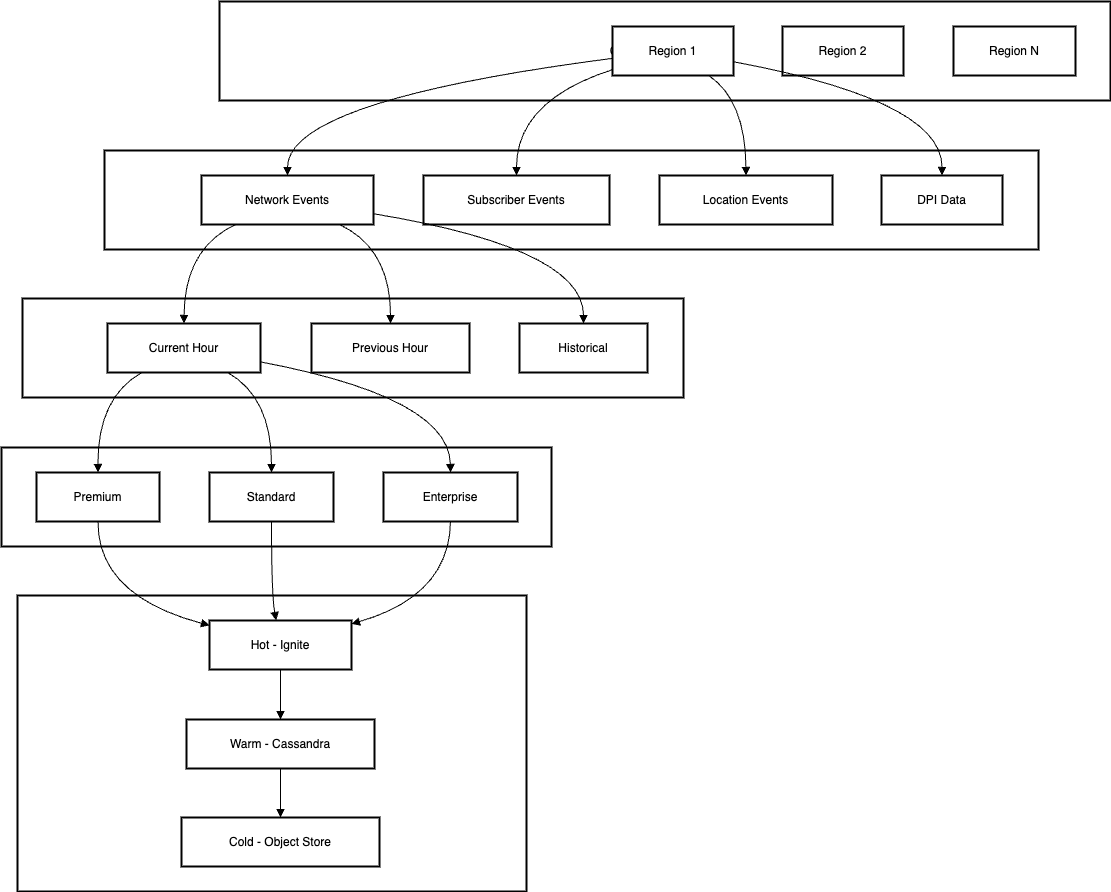
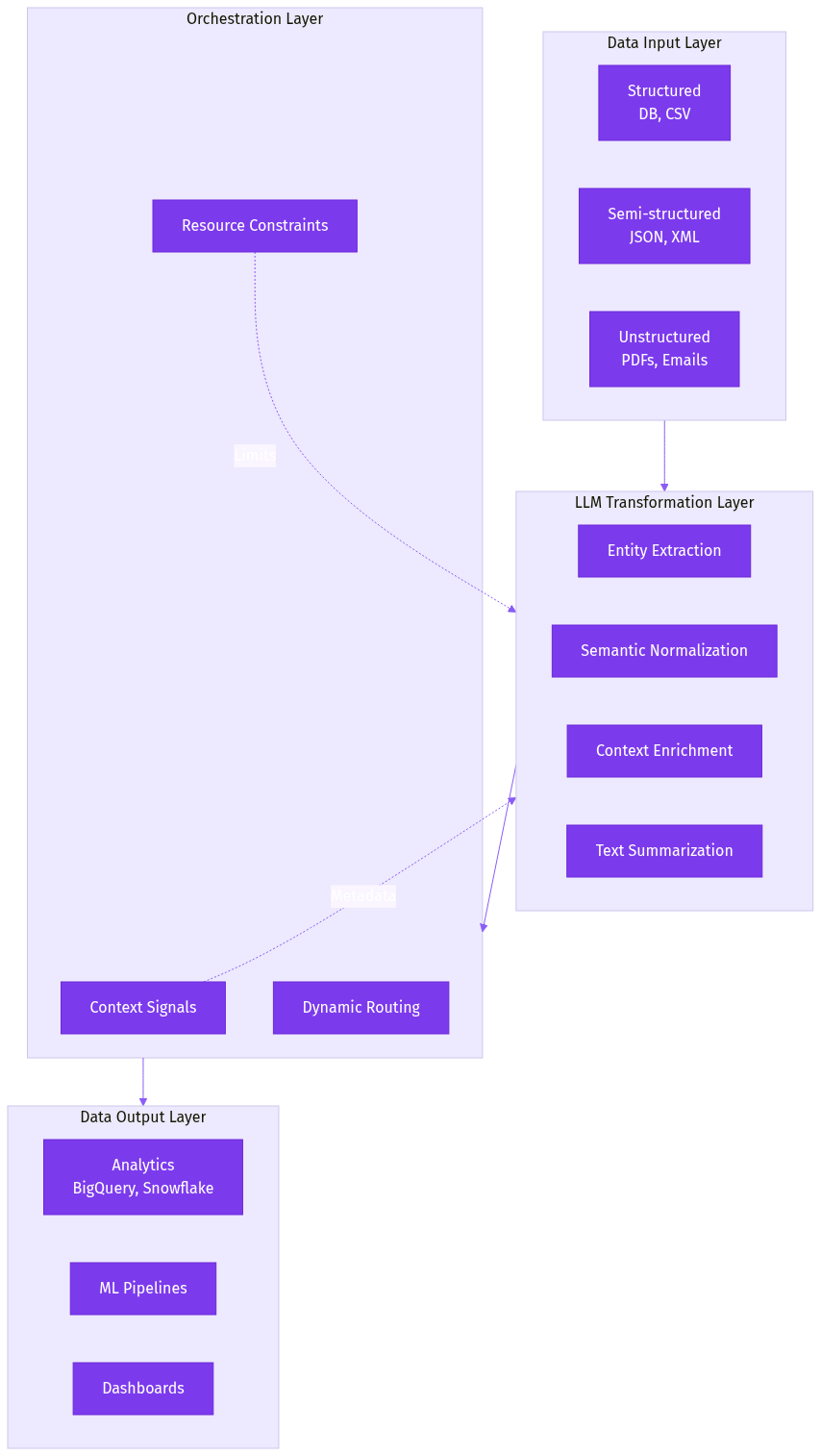
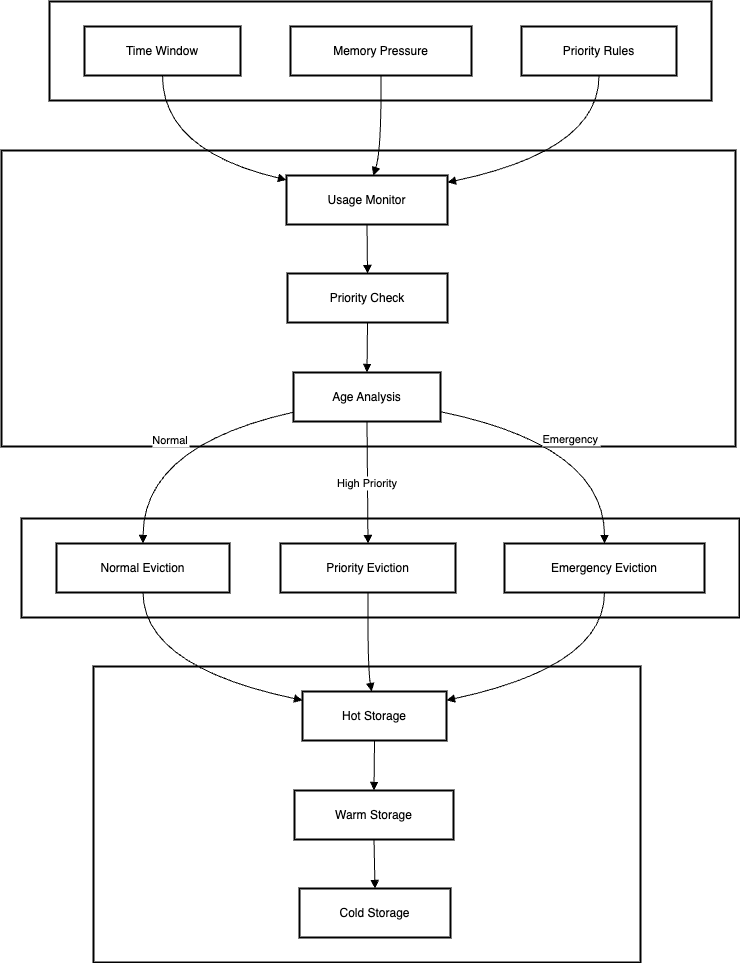
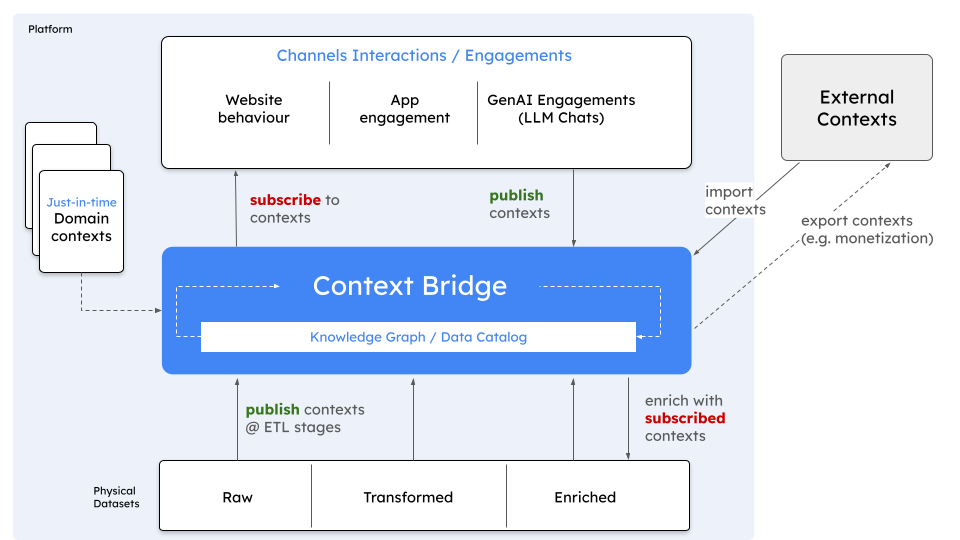
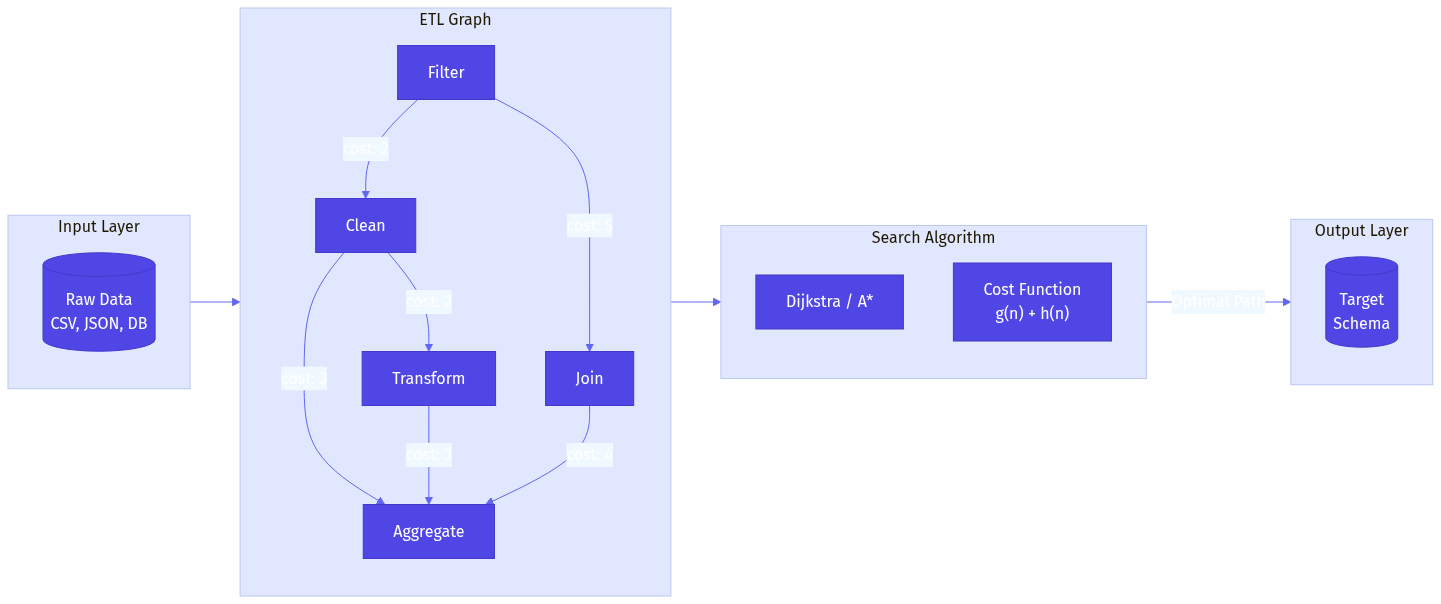
Traditional data warehouses are struggling to keep up with modern demands. Enter Dynamic Context Engines (DCEs) - real-time, path-aware platforms that enrich data with context for smarter, faster decisions. Discover why they're the future of data analytics.