Note: This blog post covers generative AI / autonomous agents. For traditional software agents system’s view refer this post for Banking/ FSI here.
Remember that time you called customer service and had to explain your problem five times to five different people? Well, welcome to the world of autonomous AI agents, where we’re teaching machines to do better (and maybe remember things longer than a goldfish).
In this technical deep dive, we’re going to explore how to build a multi-agent system that not only handles customer service but does it with style. Think of it as teaching a group of AI agents to work together like a well-oiled machine, or at least better than that one team meeting where everyone talked over each other.
We’ll cover everything from sophisticated memory systems (because even AI needs help remembering things) to prompt engineering that actually evolves (unlike my New Year’s resolutions). Get ready for some serious code, real-world examples, and maybe a few dad jokes along the way.
System Architecture
Our autonomous agent system comprises multiple specialized agents, each powered by LLMs but trained for specific tasks. The system architecture is designed to handle complex customer queries while maintaining context and ensuring consistent, accurate responses.
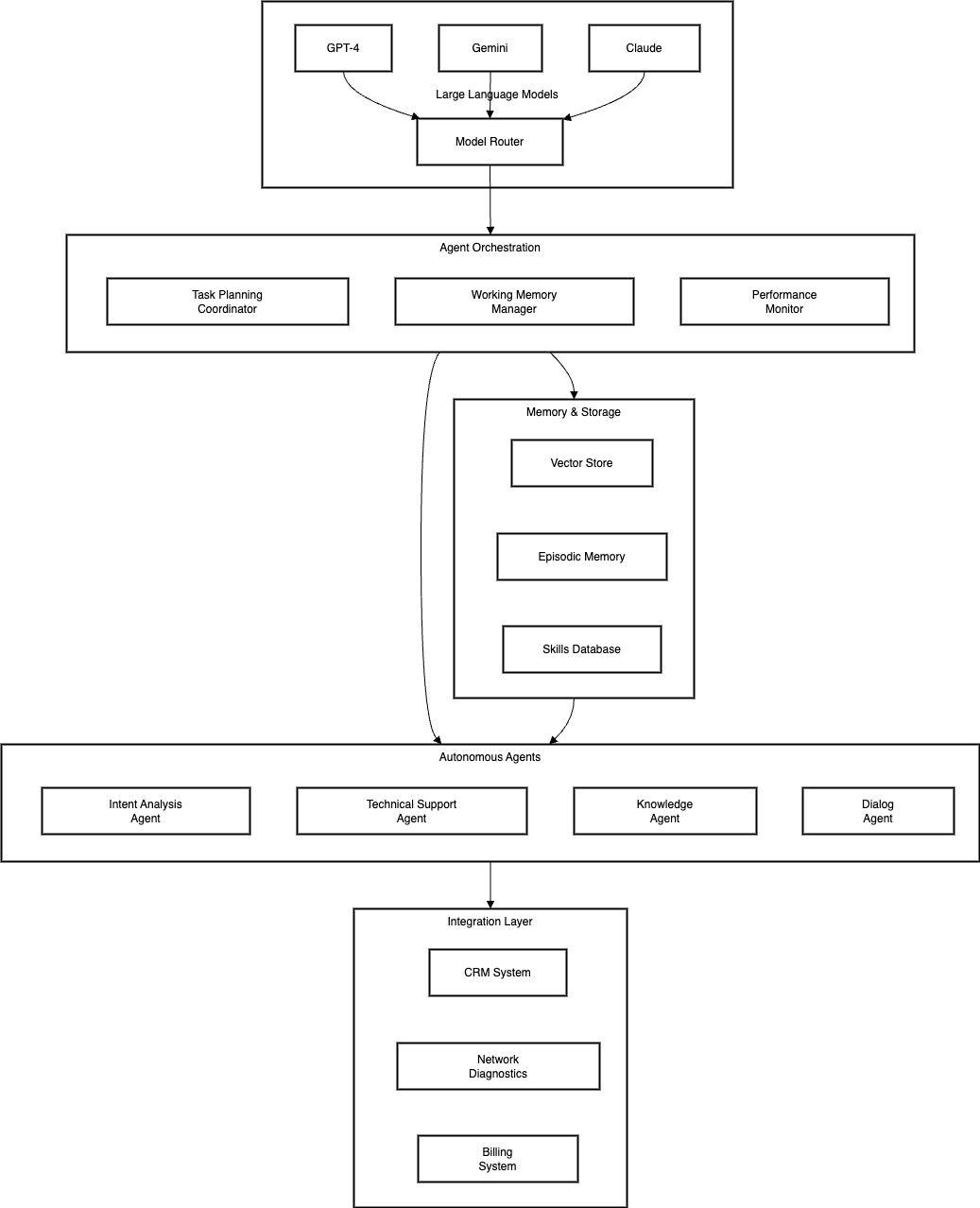
Key Components
-
Foundation Model Layer
- Handles core language understanding and generation
- Enables zero-shot and few-shot learning capabilities
- Provides base reasoning capabilities for agents
-
Agent Controller
- Orchestrates agent interactions
- Manages task decomposition and planning
- Monitors agent performance and handles failures
-
Specialized Agents
- Intent Analysis Agent: Understands customer needs
- Technical Diagnostic Agent: Handles network issues
- Knowledge Agents: Manage policy and product information
Let’s dive into the implementation details.
Agent Implementation
Here’s how we implement our core autonomous agents:
from typing import Dict, List, Optional
from dataclasses import dataclass
from enum import Enum
import asyncio
import anthropic
import chromadb
from pydantic import BaseModel
class AgentRole(Enum):
PLANNER = "planner"
INTENT = "intent"
TECHNICAL = "technical"
KNOWLEDGE = "knowledge"
DIALOGUE = "dialogue"
@dataclass
class AgentContext:
conversation_history: List[Dict]
customer_profile: Dict
current_intent: str
relevant_policies: List[Dict]
system_status: Dict
class BaseAgent:
def __init__(self,
llm_client: anthropic.AsyncAnthropic,
vector_store: chromadb.AsyncClient,
role: AgentRole):
self.llm = llm_client
self.vector_store = vector_store
self.role = role
self.system_prompt = self._load_role_prompt()
async def _load_role_prompt(self) -> str:
"""Load role-specific prompt from vector store"""
prompts = await self.vector_store.get_collection("agent_prompts")
role_prompt = await prompts.get(
where={"role": self.role.value}
)
return role_prompt["text"]
async def think(self, context: AgentContext) -> str:
"""Internal reasoning step"""
reasoning = await self.llm.messages.create(
system_prompt=self.system_prompt,
messages=[{
"role": "user",
"content": f"Given the context: {context}, "
f"what should be our next action?"
}]
)
return reasoning.content
class PlanningAgent(BaseAgent):
def __init__(self,
llm_client: anthropic.AsyncAnthropic,
vector_store: chromadb.AsyncClient,
agents: Dict[AgentRole, BaseAgent]):
super().__init__(llm_client, vector_store, AgentRole.PLANNER)
self.agents = agents
async def plan_resolution(self,
query: str,
context: AgentContext) -> Dict:
# Decompose problem into steps
plan = await self._create_plan(query, context)
# Execute plan steps with appropriate agents
results = []
for step in plan:
agent = self.agents[step.agent_role]
result = await agent.execute(step, context)
results.append(result)
context = self._update_context(context, result)
# Synthesize final response
return await self._synthesize_response(results, context)
async def _create_plan(self,
query: str,
context: AgentContext) -> List[Dict]:
# Use LLM to create resolution plan
response = await self.llm.messages.create(
system_prompt=self.system_prompt,
messages=[{
"role": "user",
"content": f"Create a plan to resolve: {query}"
}]
)
return self._parse_plan(response.content)
class TechnicalAgent(BaseAgent):
def __init__(self,
llm_client: anthropic.AsyncAnthropic,
vector_store: chromadb.AsyncClient,
network_api: NetworkAPI):
super().__init__(llm_client, vector_store, AgentRole.TECHNICAL)
self.network_api = network_api
async def diagnose_issue(self,
symptoms: List[str],
context: AgentContext) -> Dict:
# Get relevant diagnostic procedures
procedures = await self._get_diagnostic_procedures(symptoms)
# Run diagnostic tests
results = []
for procedure in procedures:
result = await self.network_api.run_diagnostic(
procedure, context.customer_profile
)
results.append(result)
# Analyze results with LLM
analysis = await self._analyze_results(results, context)
return analysis
class KnowledgeAgent(BaseAgent):
def __init__(self,
llm_client: anthropic.AsyncAnthropic,
vector_store: chromadb.AsyncClient):
super().__init__(llm_client, vector_store, AgentRole.KNOWLEDGE)
async def retrieve_knowledge(self,
query: str,
context: AgentContext) -> Dict:
# Perform RAG to get relevant information
docs = await self._retrieve_documents(query, context)
# Synthesize knowledge with LLM
synthesis = await self.llm.messages.create(
system_prompt=self.system_prompt,
messages=[{
"role": "user",
"content": f"Synthesize this information: {docs}"
}]
)
return {"synthesis": synthesis.content, "sources": docs}
Agent Interaction Flow
The sequence diagram below shows how agents collaborate to resolve customer queries:
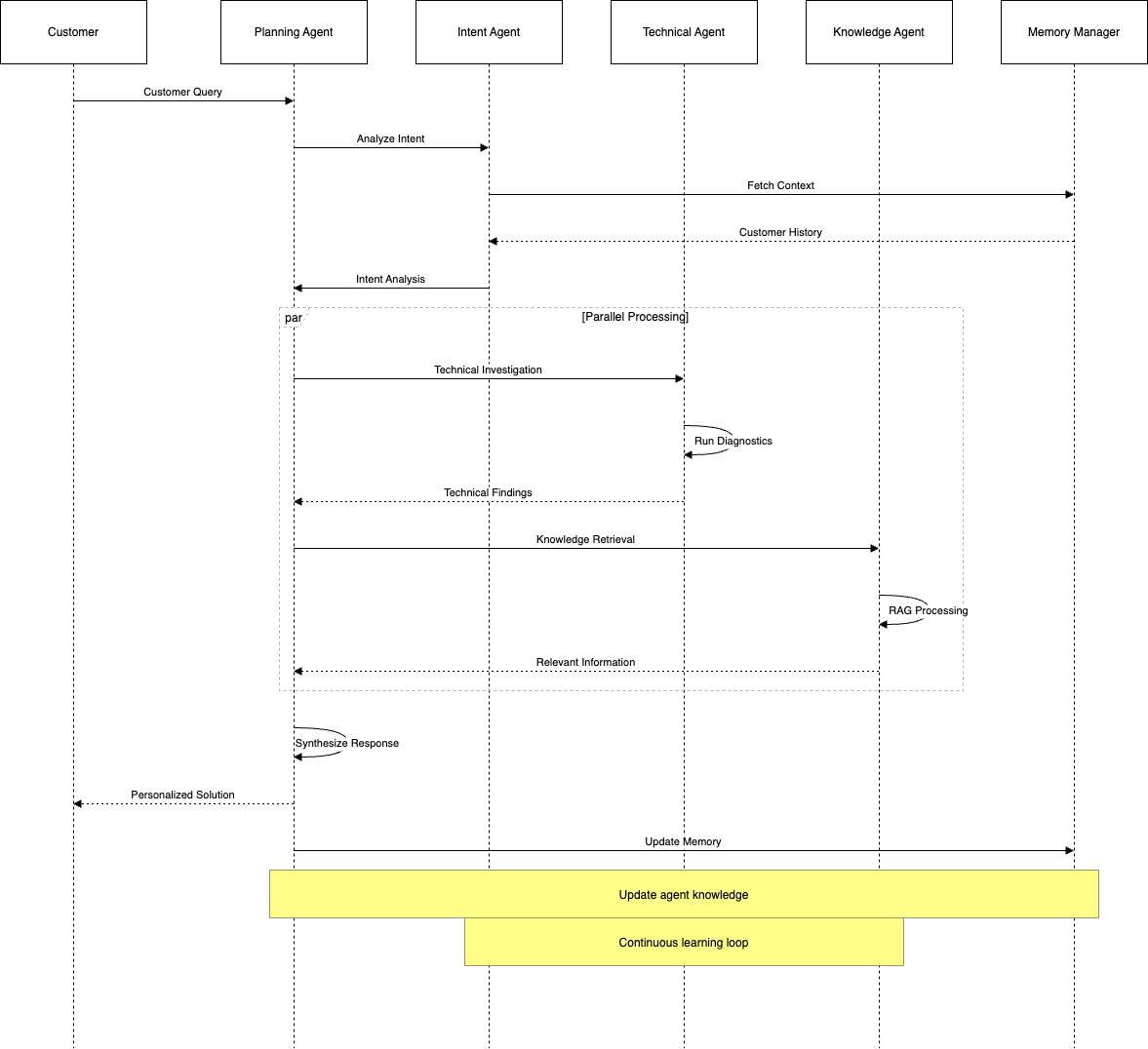
Let’s examine a real customer service scenario:
async def handle_network_issue(
customer_query: str,
customer_id: str,
planner: PlanningAgent
) -> Dict:
# Initialize context
context = await build_initial_context(customer_id)
# Plan resolution
resolution = await planner.plan_resolution(
customer_query, context
)
# Execute with continuous monitoring
try:
result = await execute_resolution_plan(
resolution, context
)
# Update agent knowledge
await update_agent_knowledge(result)
return result
except Exception as e:
# Handle failures gracefully
return await handle_resolution_failure(e, context)
Memory and Learning
Our agents maintain and learn from interactions through:
- Episodic Memory
class MemoryManager:
def __init__(self, vector_store: chromadb.AsyncClient):
self.vector_store = vector_store
async def store_interaction(self,
interaction: Dict,
context: AgentContext):
# Store in vector database for retrieval
await self.vector_store.add(
collection_name="interactions",
documents=[interaction],
metadata={
"customer_id": context.customer_profile["id"],
"intent": context.current_intent,
"outcome": interaction["outcome"]
}
)
async def retrieve_similar_cases(self,
current_case: Dict,
limit: int = 5) -> List[Dict]:
# Find similar past interactions
similar = await self.vector_store.query(
collection_name="interactions",
query_texts=[current_case["description"]],
n_results=limit
)
return similar
- Continuous Learning
class AgentLearningManager:
def __init__(self,
llm_client: anthropic.AsyncAnthropic,
vector_store: chromadb.AsyncClient):
self.llm = llm_client
self.vector_store = vector_store
async def learn_from_interaction(self,
interaction: Dict,
outcome: Dict):
# Extract learning points
learnings = await self._extract_learnings(
interaction, outcome
)
# Update agent knowledge
await self._update_knowledge_base(learnings)
# Refine agent prompts if needed
await self._refine_prompts(learnings)
Performance Monitoring
We monitor agent performance through:
- Resolution Metrics
class PerformanceMonitor:
async def track_resolution(self,
interaction: Dict,
metrics: Dict):
# Track resolution time
resolution_time = metrics["resolution_time"]
# Track customer satisfaction
satisfaction = metrics["satisfaction_score"]
# Track agent effectiveness
agent_metrics = metrics["agent_metrics"]
await self._store_metrics(
interaction["id"],
resolution_time,
satisfaction,
agent_metrics
)
Detailed Agent Interactions
Let’s examine specific scenarios showing how agents collaborate:
Scenario 1: Complex Network Issue Resolution
async def handle_complex_network_issue(
query: str,
context: AgentContext,
agents: AgentSystem
) -> Resolution:
# Initial intent analysis
intent = await agents.intent_agent.analyze(query)
if intent.confidence < 0.8:
# Engage dialog agent for clarification
clarification = await agents.dialog_agent.get_clarification(
query, intent.unclear_aspects
)
intent = await agents.intent_agent.analyze(clarification)
# Technical diagnosis phase
tech_diagnosis = await agents.technical_agent.diagnose(intent)
if tech_diagnosis.requires_network_scan:
# Parallel processing of network diagnostics
async with agents.start_parallel_tasks() as tasks:
tasks.add(agents.technical_agent.scan_network(
context.customer_profile.location
))
tasks.add(agents.knowledge_agent.get_related_issues(
tech_diagnosis.symptoms
))
scan_results, known_issues = await tasks.complete()
# Synthesize solution
solution = await agents.planner.create_solution(
intent=intent,
diagnosis=tech_diagnosis,
scan_results=scan_results,
known_issues=known_issues
)
return solution
# Example usage
async def real_world_example():
query = """My internet keeps dropping every 30 minutes,
and I've already restarted the router twice.
I'm working from home and need this fixed urgently."""
context = AgentContext(
customer_id="C123",
service_type="Fiber",
priority="High",
history=await get_customer_history("C123")
)
solution = await handle_complex_network_issue(query, context, agents)
Scenario 2: Multi-Agent Learning from Customer Interactions
class AgentLearningSystem:
def __init__(self, vector_store: VectorStore,
episodic_memory: EpisodicMemory):
self.vector_store = vector_store
self.episodic_memory = episodic_memory
self.learning_buffer = []
async def learn_from_interaction(self,
interaction: Interaction,
outcome: Outcome):
# Extract learning points
learning_points = await self._analyze_interaction(interaction, outcome)
# Update agent skills
if learning_points.new_patterns:
await self._update_agent_skills(learning_points.new_patterns)
# Store successful approaches
if outcome.was_successful:
await self.episodic_memory.store_success_pattern(
interaction.flow,
outcome.resolution_path
)
# Learn from failures
if not outcome.was_successful:
await self._analyze_failure(interaction, outcome)
async def _analyze_failure(self,
interaction: Interaction,
outcome: Outcome):
# Identify failure point
failure_analysis = await self._identify_failure_point(
interaction.flow,
outcome
)
# Update failure patterns
await self.vector_store.update_failure_patterns(
failure_analysis.pattern,
failure_analysis.context
)
# Adjust agent behaviors
await self._update_agent_strategies(
failure_analysis.recommendations
)
Edge Cases and Failure Handling
class EdgeCaseHandler:
async def handle_edge_case(self,
case: Case,
context: AgentContext) -> Resolution:
match case.type:
case EdgeCaseType.CONFLICTING_INTENTS:
return await self._handle_intent_conflict(case, context)
case EdgeCaseType.SYSTEM_UNAVAILABLE:
return await self._handle_system_outage(case, context)
case EdgeCaseType.HIGH_UNCERTAINTY:
return await self._handle_uncertainty(case, context)
async def _handle_intent_conflict(self,
case: Case,
context: AgentContext) -> Resolution:
# Get all possible intents
intents = await self.intent_agent.get_all_possible_intents(
case.query
)
# Score each intent based on context
scored_intents = await self.intent_agent.score_intents(
intents, context
)
if max(scored_intents.values()) < 0.4:
# No clear winner - need human intervention
return await self._escalate_to_human(case, context)
# Process top intent but keep others for backup
return await self._process_with_fallback(
scored_intents, context
)
async def _handle_system_outage(self,
case: Case,
context: AgentContext) -> Resolution:
# Check system status
status = await self.system_monitor.get_status()
# If critical system is down
if status.has_critical_outage:
# Use cached data if available
if cached_data := await self.cache.get(case.key):
return await self._process_with_cached_data(
case, cached_data, context
)
# Otherwise, gracefully degrade service
return await self._degrade_gracefully(case, context)
async def _handle_uncertainty(self,
case: Case,
context: AgentContext) -> Resolution:
# Analyze uncertainty sources
uncertainty = await self.analyzer.analyze_uncertainty(
case, context
)
if uncertainty.is_data_related:
# Try to gather more data
return await self._gather_additional_data(case, context)
if uncertainty.is_knowledge_related:
# Consult knowledge base or escalate
return await self._consult_knowledge_base(case, context)
# Default to safe action
return await self._take_safe_action(case, context)
Learning from Edge Cases
class EdgeCaseLearningSystem:
async def learn_from_edge_case(self,
case: EdgeCase,
resolution: Resolution):
# Record the edge case pattern
await self.vector_store.add_edge_case_pattern(
case.pattern,
resolution.successful_approach
)
# Update agent behavior models
for agent in case.involved_agents:
await self._update_agent_model(
agent,
case.learnings
)
# If this is a new pattern, add to monitoring
if case.is_novel_pattern:
await self.monitor.add_pattern_to_watch(
case.pattern,
resolution.indicators
)
async def _update_agent_model(self,
agent: BaseAgent,
learnings: Dict[str, Any]):
# Update agent's decision model
await agent.update_decision_model(learnings)
# Adjust confidence thresholds if needed
if learnings.confidence_issues:
await agent.adjust_confidence_thresholds(
learnings.confidence_data
)
# Update interaction patterns
await agent.add_interaction_pattern(
learnings.new_pattern
)
Agent Monitoring and Evaluation
Monitoring autonomous agents requires tracking both technical metrics and cognitive performance. Here’s our implementation:
class AgentMonitoringSystem:
def __init__(self):
self.metrics_store = MetricsStore()
self.alert_system = AlertSystem()
self.performance_evaluator = PerformanceEvaluator()
async def monitor_agent_performance(self,
agent: BaseAgent,
interaction: Interaction):
# Track core metrics
metrics = {
'response_time': interaction.duration,
'token_usage': interaction.token_count,
'confidence_scores': interaction.confidence_metrics,
'resolution_success': interaction.was_successful
}
# Track cognitive metrics
cognitive_metrics = await self._evaluate_cognitive_performance(
agent, interaction
)
# Track resource usage
resource_metrics = await self._track_resource_usage(
agent, interaction
)
# Store consolidated metrics
await self.metrics_store.store(
agent_id=agent.id,
metrics={**metrics, **cognitive_metrics, **resource_metrics},
timestamp=interaction.timestamp
)
# Check for anomalies
await self._check_anomalies(agent, metrics)
async def _evaluate_cognitive_performance(self,
agent: BaseAgent,
interaction: Interaction):
return {
'reasoning_quality': await self._assess_reasoning(
interaction.reasoning_chain
),
'context_relevance': await self._assess_context_usage(
interaction.used_context,
interaction.available_context
),
'knowledge_application': await self._assess_knowledge_usage(
interaction.knowledge_references
)
}
class PerformanceEvaluator:
def __init__(self, llm_client: AsyncAnthropic):
self.llm = llm_client
self.evaluation_prompts = self._load_evaluation_prompts()
async def evaluate_interaction(self,
interaction: Interaction) -> EvalResult:
# Evaluate based on multiple criteria
results = await asyncio.gather(
self._evaluate_accuracy(interaction),
self._evaluate_efficiency(interaction),
self._evaluate_appropriateness(interaction),
self._evaluate_creativity(interaction)
)
# Aggregate scores
return self._aggregate_scores(results)
async def _evaluate_accuracy(self, interaction: Interaction):
prompt = f"""Evaluate the accuracy of this agent interaction:
Context: {interaction.context}
User Query: {interaction.query}
Agent Response: {interaction.response}
Reasoning Chain: {interaction.reasoning_chain}
Score the following aspects:
1. Factual accuracy
2. Logical consistency
3. Solution completeness
4. Validation of assumptions
Provide a score (1-10) for each aspect and explain your reasoning.
"""
evaluation = await self.llm.messages.create(
system_prompt=self.evaluation_prompts['accuracy'],
messages=[{"role": "user", "content": prompt}]
)
return self._parse_evaluation(evaluation.content)
Advanced Memory Systems
Our memory system is designed to handle multiple types of memory with different retention patterns:
class HierarchicalMemorySystem:
def __init__(self):
self.working_memory = WorkingMemory()
self.episodic_memory = EpisodicMemory()
self.semantic_memory = SemanticMemory()
self.procedural_memory = ProceduralMemory()
async def store_interaction(self,
interaction: Interaction,
memory_type: MemoryType):
match memory_type:
case MemoryType.WORKING:
await self.working_memory.store(
interaction,
ttl=timedelta(minutes=30)
)
case MemoryType.EPISODIC:
await self.episodic_memory.store(
interaction,
context=interaction.context
)
case MemoryType.SEMANTIC:
knowledge = await self._extract_knowledge(interaction)
await self.semantic_memory.store(knowledge)
case MemoryType.PROCEDURAL:
procedure = await self._extract_procedure(interaction)
await self.procedural_memory.store(procedure)
class SemanticMemory:
def __init__(self, vector_store: ChromaDB):
self.vector_store = vector_store
self.knowledge_graph = NetworkX()
async def store_knowledge(self, knowledge: Knowledge):
# Store in vector database
await self.vector_store.add(
collection_name="semantic_memory",
documents=[knowledge.content],
metadata=knowledge.metadata
)
# Update knowledge graph
await self._update_knowledge_graph(knowledge)
async def retrieve_relevant_knowledge(self,
query: str,
context: Context) -> List[Knowledge]:
# Hybrid search using both vector similarity and graph relationships
vector_results = await self.vector_store.query(
collection_name="semantic_memory",
query_texts=[query],
n_results=10
)
graph_results = await self._graph_search(query, context)
# Merge and rank results
return self._merge_and_rank_results(vector_results, graph_results)
class EpisodicMemory:
def __init__(self, vector_store: ChromaDB):
self.vector_store = vector_store
self.episode_index = {}
async def store_episode(self,
episode: Episode,
context: Context):
# Create episode embedding
embedding = await self._create_episode_embedding(episode)
# Store in vector database
await self.vector_store.add(
collection_name="episodic_memory",
documents=[episode.summary],
embeddings=[embedding],
metadata={
"timestamp": episode.timestamp,
"outcome": episode.outcome,
"context_hash": context.hash
}
)
# Update episode index
self.episode_index[episode.id] = {
"embedding": embedding,
"context": context
}
Prompt Engineering for Different Agents
Different agents require specialized prompts to perform their roles effectively:
Intent Analysis Agent
INTENT_AGENT_PROMPT = """You are an Intent Analysis Agent in a telecom customer service system. Your role is to:
1. Precisely identify customer intent from their queries
2. Detect multiple or hidden intents
3. Assess intent confidence
4. Identify required context for resolution
Given a customer query, analyze it using this structure:
1. Primary Intent: Main customer goal
2. Secondary Intents: Additional or implied needs
3. Required Information: What we need to know
4. Confidence Score: How certain are you (0-1)
5. Context Needs: What additional context would help
Example:
Query: "My internet is slow and I want to know if I can upgrade my plan"
Analysis:
- Primary Intent: Service Quality Issue (internet speed)
- Secondary Intent: Plan Upgrade Information
- Required Information: Current plan, Speed tests, Location
- Confidence: 0.95
- Context Needs: Current plan details, Account history
Approach each query systematically and be explicit about uncertainty.
"""
TECHNICAL_AGENT_PROMPT = """You are a Technical Support Agent specializing in telecom issues. Your role is to:
1. Diagnose technical issues from symptoms
2. Design step-by-step troubleshooting plans
3. Interpret diagnostic results
4. Recommend solutions
Given a technical issue, follow this process:
1. Initial Assessment
- Classify the issue type
- Identify potential causes
- List required diagnostics
2. Diagnosis Plan
- Order tests by priority
- Consider dependencies
- Note expected outcomes
3. Solution Design
- Start with least intrusive solutions
- Include fallback options
- Consider customer impact
Example:
Issue: "Intermittent internet disconnections"
Assessment:
- Type: Connectivity Issue
- Potential Causes: Signal issues, Equipment problems, Network congestion
- Required Diagnostics: Signal strength test, Equipment status, Network load check
Remember to:
- Be precise in technical language
- Explain technical concepts clearly
- Consider customer technical expertise level
- Document all diagnostic steps
"""
KNOWLEDGE_AGENT_PROMPT = """You are a Knowledge Management Agent in a telecom support system. Your role is to:
1. Retrieve and synthesize relevant information
2. Apply policies and procedures correctly
3. Maintain information accuracy
4. Identify knowledge gaps
When processing queries:
1. Information Retrieval
- Search relevant knowledge bases
- Check policy updates
- Verify information currency
2. Knowledge Synthesis
- Combine multiple sources
- Resolve conflicts
- Ensure consistency
3. Application
- Context-appropriate responses
- Policy compliance
- Clear explanations
Example:
Query: "Customer asking about 5G upgrade policy"
Process:
1. Check current 5G policies
2. Verify customer eligibility rules
3. Review recent policy updates
4. Synthesize into clear response
Remember:
- Cite sources and policy references
- Note information freshness
- Flag ambiguities or conflicts
- Suggest knowledge base updates
"""
class PromptManager:
def __init__(self):
self.prompt_templates = {
AgentType.INTENT: INTENT_AGENT_PROMPT,
AgentType.TECHNICAL: TECHNICAL_AGENT_PROMPT,
AgentType.KNOWLEDGE: KNOWLEDGE_AGENT_PROMPT
}
async def generate_prompt(self,
agent_type: AgentType,
context: Context) -> str:
base_prompt = self.prompt_templates[agent_type]
# Customize prompt based on context
customized_prompt = await self._customize_prompt(
base_prompt, context
)
# Add relevant examples
examples = await self._get_relevant_examples(
agent_type, context
)
return self._format_final_prompt(
customized_prompt, examples
)
Advanced Agent Prompts and Evolution
class EvolvingPromptSystem:
def __init__(self, llm_client: AsyncAnthropic):
self.llm = llm_client
self.prompt_versions = {}
self.performance_metrics = {}
async def evolve_prompt(self,
agent_type: AgentType,
performance_data: List[PerformanceMetric]) -> str:
"""Evolve prompts based on performance data"""
current_prompt = await self.get_current_prompt(agent_type)
# Analyze performance patterns
analysis = await self._analyze_performance_patterns(
agent_type, performance_data
)
# Generate prompt improvements
improvements = await self._generate_improvements(
current_prompt, analysis
)
# Test new prompt variations
test_results = await self._test_prompt_variations(improvements)
# Select best performing variant
new_prompt = await self._select_best_prompt(test_results)
return new_prompt
async def _analyze_performance_patterns(self,
agent_type: AgentType,
performance_data: List[PerformanceMetric]):
# Group by performance aspects
grouped_data = {
'accuracy': [],
'clarity': [],
'efficiency': [],
'adherence_to_role': []
}
for metric in performance_data:
grouped_data['accuracy'].append(metric.accuracy_score)
grouped_data['clarity'].append(metric.clarity_score)
grouped_data['efficiency'].append(metric.efficiency_score)
grouped_data['adherence_to_role'].append(metric.role_adherence)
return {
'weak_areas': self._identify_weak_areas(grouped_data),
'improvement_opportunities': self._identify_improvements(grouped_data)
}
class PromptLibrary:
"""Example prompts for different agent types with evolution capabilities"""
DIALOGUE_AGENT_BASE = """You are a Dialog Management Agent in a telecom customer service system.
Primary Objectives:
1. Maintain natural, context-aware conversations
2. Elicit necessary information efficiently
3. Show appropriate empathy
4. Guide conversations productively
Conversation Guidelines:
1. Start with open-ended questions
2. Follow up on emotional cues
3. Validate customer concerns
4. Summarize understanding regularly
Example Dialogue:
Customer: "I'm really frustrated with my service!"
Response: "I understand your frustration. Could you tell me more about what's happening with your service?"
Remember to:
- Acknowledge emotions
- Stay focused on resolution
- Use appropriate tone
- Maintain conversation history
"""
ESCALATION_AGENT_BASE = """You are an Escalation Management Agent.
Your role is to:
1. Identify escalation triggers
2. Manage handoffs appropriately
3. Preserve context during escalation
4. Track escalation patterns
Escalation Criteria:
1. Technical complexity
2. Customer satisfaction risk
3. Regulatory requirements
4. Business impact
Example:
Scenario: Complex billing dispute with technical components
Action: Escalate to Billing Specialist with Technical Consult
Remember:
- Document escalation reasons
- Ensure smooth handoffs
- Follow up on resolution
- Learn from patterns
"""
class PromptEvolution:
async def evolve_dialogue_prompt(self,
base_prompt: str,
performance_data: Dict[str, float]) -> str:
"""Evolve dialogue prompt based on performance metrics"""
enhancements = []
# If empathy scores are low
if performance_data['empathy_score'] < 0.7:
enhancements.append("""
Enhanced Empathy Guidelines:
1. Recognize emotional undertones
2. Use acknowledgment phrases
3. Show understanding through rephrasing
4. Validate customer feelings
""")
# If information gathering is inefficient
if performance_data['information_efficiency'] < 0.8:
enhancements.append("""
Efficient Information Gathering:
1. Use targeted follow-up questions
2. Summarize gathered information
3. Confirm critical details
4. Track information gaps
""")
return self._merge_prompt_enhancements(base_prompt, enhancements)
Advanced Monitoring Metrics and Thresholds
class MonitoringSystem:
def __init__(self):
self.metrics_store = MetricsStore()
self.thresholds = self._load_thresholds()
async def monitor_agent_health(self,
agent: BaseAgent,
time_window: timedelta):
metrics = await self.metrics_store.get_metrics(
agent_id=agent.id,
window=time_window
)
# Performance Metrics
performance_health = await self._check_performance_metrics(metrics)
# Resource Usage
resource_health = await self._check_resource_metrics(metrics)
# Cognitive Metrics
cognitive_health = await self._check_cognitive_metrics(metrics)
return AgentHealth(
performance=performance_health,
resources=resource_health,
cognitive=cognitive_health
)
def _load_thresholds(self) -> Dict[str, ThresholdConfig]:
return {
'response_time': ThresholdConfig(
warning=1.5, # seconds
critical=3.0,
trend_window=timedelta(hours=1)
),
'token_usage': ThresholdConfig(
warning=1000,
critical=2000,
trend_window=timedelta(minutes=5)
),
'error_rate': ThresholdConfig(
warning=0.05, # 5%
critical=0.10,
trend_window=timedelta(minutes=15)
),
'cognitive_drift': ThresholdConfig(
warning=0.15, # drift from baseline
critical=0.30,
trend_window=timedelta(hours=24)
)
}
Memory Retrieval Strategies
class MemoryRetrievalSystem:
def __init__(self,
vector_store: VectorStore,
graph_store: NetworkX):
self.vector_store = vector_store
self.graph_store = graph_store
async def retrieve_relevant_memories(self,
query: str,
context: Context) -> MemorySet:
# Multi-stage retrieval process
memories = MemorySet()
# 1. Quick working memory check
working_mem = await self._check_working_memory(query)
if working_mem.is_relevant:
memories.add(working_mem)
# 2. Semantic search in episodic memory
episodic_mem = await self._search_episodic_memory(
query, context
)
memories.add(episodic_mem)
# 3. Knowledge graph traversal
graph_memories = await self._traverse_knowledge_graph(
query, context
)
memories.add(graph_memories)
# 4. Synthesize and rank memories
ranked_memories = await self._rank_memories(
memories, query, context
)
return ranked_memories
async def _search_episodic_memory(self,
query: str,
context: Context) -> List[Memory]:
# Hybrid search strategy
vector_results = await self.vector_store.similarity_search(
query,
filter=self._build_context_filter(context)
)
temporal_results = await self._temporal_search(
query, context
)
causal_results = await self._causal_chain_search(
query, context
)
return self._merge_search_results(
vector_results,
temporal_results,
causal_results
)
Memory Interaction in Complex Scenarios
class MemoryInteractionManager:
def __init__(self,
memory_system: HierarchicalMemorySystem):
self.memory = memory_system
async def handle_complex_query(self,
query: ComplexQuery,
context: Context) -> Response:
# Initialize memory workspace
workspace = MemoryWorkspace()
# 1. Access working memory for immediate context
working_context = await self.memory.working_memory.get_context(
query.session_id
)
workspace.add(working_context)
# 2. Retrieve relevant episodic memories
episodes = await self.memory.episodic_memory.find_similar(
query.pattern,
limit=5
)
workspace.add(episodes)
# 3. Extract semantic knowledge
knowledge = await self.memory.semantic_memory.get_relevant(
query.topics
)
workspace.add(knowledge)
# 4. Apply procedural memories
procedures = await self.memory.procedural_memory.get_procedures(
query.task_type
)
workspace.add(procedures)
# 5. Synthesize response
response = await self._synthesize_response(
query, workspace
)
# 6. Update memories
await self._update_memories(
query, response, workspace
)
return response
async def _synthesize_response(self,
query: ComplexQuery,
workspace: MemoryWorkspace) -> Response:
# Create memory layers
layers = [
workspace.get_layer(MemoryType.WORKING),
workspace.get_layer(MemoryType.EPISODIC),
workspace.get_layer(MemoryType.SEMANTIC),
workspace.get_layer(MemoryType.PROCEDURAL)
]
# Build response using all memory types
synthesis = ResponseSynthesizer(layers)
response = await synthesis.create_response(query)
return response
class MemoryWorkspace:
"""Manages active memories during processing"""
def __init__(self):
self.layers = {
MemoryType.WORKING: WorkingMemoryLayer(),
MemoryType.EPISODIC: EpisodicMemoryLayer(),
MemoryType.SEMANTIC: SemanticMemoryLayer(),
MemoryType.PROCEDURAL: ProceduralMemoryLayer()
}
def add(self, memory: Memory):
layer = self.layers[memory.type]
layer.add(memory)
def get_layer(self, memory_type: MemoryType) -> MemoryLayer:
return self.layers[memory_type]
These implementations demonstrate:
-
Prompt Evolution:
- Performance-based prompt improvement
- Systematic analysis of weak areas
- A/B testing of prompt variations
- Role-specific prompt templates
-
Monitoring Metrics:
- Comprehensive metric categories
- Configurable thresholds
- Trend analysis
- Health checks at multiple levels
-
Memory Retrieval:
- Multi-strategy retrieval
- Context-aware searching
- Hybrid ranking systems
- Efficient filtering
-
Memory Interaction:
- Coordinated memory access
- Memory workspace management
- Cross-memory synthesis
- Dynamic updates
Complex Memory Interaction Scenarios
Let’s examine how different memory types interact in real-world scenarios:
class ComplexScenarioHandler:
"""Handles complex customer service scenarios requiring multiple memory types"""
async def handle_service_migration(self,
customer_id: str,
new_service: ServiceType) -> Resolution:
"""Example: Customer moving house with service transfer and upgrades"""
# Initialize memory workspace
workspace = MemoryWorkspace()
# 1. Retrieve customer history
history = await self.memory.episodic_memory.get_customer_history(
customer_id,
relevance_window=timedelta(months=6)
)
# 2. Get current service configuration
current_config = await self.memory.working_memory.get_service_config(
customer_id
)
# 3. Access migration procedures
migration_knowledge = await self.memory.semantic_memory.get_knowledge(
topics=['service_migration', new_service.value]
)
# 4. Get location-specific procedures
location_procedures = await self.memory.procedural_memory.get_procedures(
category='location_change',
service_type=new_service
)
try:
# Synthesize migration plan
plan = await self._create_migration_plan(
history=history,
current_config=current_config,
knowledge=migration_knowledge,
procedures=location_procedures
)
# Execute migration steps
result = await self._execute_migration(plan)
# Update all memory types with new information
await self._update_memories(result)
return result
except Exception as e:
# Handle failures and update memory
await self._handle_migration_failure(e)
raise
async def handle_billing_dispute(self,
dispute: BillingDispute) -> Resolution:
"""Example: Complex billing dispute requiring historical analysis"""
# Access relevant memories across systems
billing_history = await self.memory.episodic_memory.get_billing_history(
customer_id=dispute.customer_id,
time_range=dispute.dispute_period
)
service_changes = await self.memory.episodic_memory.get_service_changes(
customer_id=dispute.customer_id,
time_range=dispute.dispute_period
)
policy_knowledge = await self.memory.semantic_memory.get_policies(
categories=['billing', 'disputes', 'adjustments']
)
resolution_procedures = await self.memory.procedural_memory.get_procedures(
category='billing_dispute',
dispute_type=dispute.type
)
# Analyze dispute using all memory types
analysis = await self._analyze_dispute(
dispute=dispute,
billing_history=billing_history,
service_changes=service_changes,
policies=policy_knowledge,
procedures=resolution_procedures
)
return await self._resolve_dispute(analysis)
Anomaly Detection and Handling
class AnomalyDetectionSystem:
"""Detects and handles various types of anomalies in agent behavior"""
def __init__(self):
self.anomaly_patterns = self._load_anomaly_patterns()
self.alert_system = AlertSystem()
async def monitor_agent_behavior(self,
agent: BaseAgent,
time_window: timedelta):
# Collect metrics
metrics = await self._collect_metrics(agent, time_window)
# Check for different types of anomalies
anomalies = []
# 1. Performance Anomalies
perf_anomalies = await self._check_performance_anomalies(metrics)
if perf_anomalies:
anomalies.extend(perf_anomalies)
# 2. Behavioral Anomalies
behavior_anomalies = await self._check_behavioral_anomalies(metrics)
if behavior_anomalies:
anomalies.extend(behavior_anomalies)
# 3. Resource Usage Anomalies
resource_anomalies = await self._check_resource_anomalies(metrics)
if resource_anomalies:
anomalies.extend(resource_anomalies)
# Handle detected anomalies
for anomaly in anomalies:
await self._handle_anomaly(agent, anomaly)
async def _check_performance_anomalies(self,
metrics: Dict[str, float]) -> List[Anomaly]:
anomalies = []
# Check response time spikes
if metrics['avg_response_time'] > self.thresholds['response_time']:
anomalies.append(
Anomaly(
type='performance',
subtype='response_time_spike',
severity=self._calculate_severity(
metrics['avg_response_time'],
self.thresholds['response_time']
)
)
)
# Check accuracy drops
if metrics['accuracy'] < self.thresholds['min_accuracy']:
anomalies.append(
Anomaly(
type='performance',
subtype='accuracy_drop',
severity=self._calculate_severity(
metrics['accuracy'],
self.thresholds['min_accuracy']
)
)
)
return anomalies
async def _handle_anomaly(self,
agent: BaseAgent,
anomaly: Anomaly):
# Log anomaly
await self._log_anomaly(anomaly)
# Take corrective action based on anomaly type
match anomaly.type:
case 'performance':
await self._handle_performance_anomaly(agent, anomaly)
case 'behavioral':
await self._handle_behavioral_anomaly(agent, anomaly)
case 'resource':
await self._handle_resource_anomaly(agent, anomaly)
# Alert appropriate teams
await self.alert_system.send_alert(
anomaly=anomaly,
agent=agent
)
Prompt Evolution Examples
class PromptEvolutionSystem:
"""Evolves prompts based on specific performance patterns"""
async def evolve_customer_service_prompt(self,
performance_data: PerformanceData) -> str:
"""Example: Evolving customer service prompt based on metrics"""
current_prompt = await self.get_current_prompt('customer_service')
# Check for specific performance patterns
enhancements = []
# Pattern 1: Low empathy scores
if performance_data.empathy_score < 0.7:
enhancements.append("""
Enhanced Empathy Guidelines:
- Always acknowledge customer emotions first
- Use phrases like "I understand how frustrating this is"
- Validate customer concerns before moving to solutions
- Show continuous engagement with active listening signals
""")
# Pattern 2: Verbose responses
if performance_data.avg_response_length > 200:
enhancements.append("""
Conciseness Guidelines:
- Start with the most important information
- Use bullet points for multiple steps
- Break complex information into digestible chunks
- Confirm understanding before elaborating
""")
# Pattern 3: Missing context utilization
if performance_data.context_usage_score < 0.8:
enhancements.append("""
Context Utilization Guidelines:
- Review full customer history before responding
- Reference previous interactions when relevant
- Connect current issue with past resolutions
- Use customer preferences in solutions
""")
return await self._merge_enhancements(current_prompt, enhancements)
async def evolve_technical_support_prompt(self,
performance_data: PerformanceData) -> str:
"""Example: Evolving technical support prompt based on metrics"""
current_prompt = await self.get_current_prompt('technical_support')
enhancements = []
# Pattern 1: Incomplete diagnostics
if performance_data.diagnostic_completion < 0.9:
enhancements.append("""
Diagnostic Completeness Guidelines:
- Always complete the full diagnostic checklist
- Document each step's results
- Explain why steps were skipped if any
- Confirm resolution with testing
""")
# Pattern 2: Poor solution explanation
if performance_data.solution_clarity < 0.8:
enhancements.append("""
Solution Clarity Guidelines:
- Break down technical concepts
- Use analogies for complex issues
- Provide step-by-step instructions
- Include verification steps
""")
return await self._merge_enhancements(current_prompt, enhancements)
Conclusion
Building autonomous agent systems is both an art and a science. While we’ve covered the technical architecture, memory systems, and monitoring capabilities in depth, the real challenge lies in creating agents that can handle the unpredictable nature of customer interactions while continuously improving their capabilities.
The future of these systems isn’t just about processing power or sophisticated algorithms - it’s about creating intelligent, adaptive agents that can work together seamlessly to solve real customer problems. Whether it’s handling complex technical troubleshooting or managing delicate customer situations, the goal is to build systems that are both powerful and practical.
Now, for the detailed technical conclusions…
Building autonomous multi-agent systems requires careful attention to several critical aspects:
-
Memory Management
- Hierarchical memory systems allow agents to maintain context and learn from experience
- Different memory types serve specific purposes and must work together seamlessly
- Efficient retrieval strategies are crucial for system performance
-
Monitoring and Adaptation
- Comprehensive monitoring helps detect and address issues early
- Anomaly detection systems protect against degraded performance
- Adaptive systems can self-improve based on performance metrics
-
Prompt Engineering
- Prompts must evolve based on performance data
- Different agent roles require specialized prompts
- Regular evaluation and refinement improve agent effectiveness
-
System Integration
- Components must work together cohesively
- Error handling should be robust and graceful
- Performance optimization needs to consider the entire system
The future of autonomous agent systems lies in their ability to:
- Learn and adapt from experience
- Handle complex scenarios with multiple memory types
- Maintain performance under varying conditions
- Evolve their capabilities over time
As these systems continue to evolve, the focus should be on:
- Improving memory retrieval efficiency
- Enhancing prompt evolution mechanisms
- Developing better monitoring and adaptation systems
- Creating more sophisticated integration patterns
Remember that building such systems requires careful balance between complexity and maintainability. Start with core functionalities and gradually add sophistication based on real-world performance data and requirements.
We will cover more in the upcoming blog posts. Stay tuned.