In Part 1 of this series, we introduced our telecommunications data platform that processes 2.5 million events per second and handles 350GB of DPI data every 15 minutes. Today, we’ll dive deep into how we designed and implemented the data partitioning strategy and managed the massive data flow through the system.
Data Characteristics and Challenges
Event Types and Volumes
-
Network Events (1.2M/sec)
- High-velocity cell tower events
- Geographically distributed
- Latency-sensitive handovers
- Variable payload sizes (200B - 2KB)
-
Subscriber Events (800K/sec)
- SIM card movements
- Device changes
- Authentication events
- Typical payload: 1-3KB
-
Location Updates (400K/sec)
- Continuous position updates
- Geographic clustering
- Time-series nature
- Payload size: 500B average
-
DPI Data (350GB/15min)
- Large batch records
- Rich protocol information
- Complex relationships
- Variable record sizes (5-50KB)
Partitioning Strategy
Key Design Principles
-
Hierarchical Partitioning
- Geographic regions (top level)
- Event types (second level)
- Time windows (third level)
- Customer segments (fourth level)
-
Data Locality
- Region-aware routing
- Rack-aware placement
- NUMA-aware processing
- Cache-aware distribution
-
Load Distribution
- Even data spread
- Hotspot prevention
- Resource balancing
- Throughput optimization
Implementation Details
Kafka Topic Design
# Network Events
network.events.${region}.${type} = {
partitions = 600,
replication.factor = 3,
min.insync.replicas = 2
}
# Subscriber Events
subscriber.events.${region}.${type} = {
partitions = 400,
replication.factor = 3,
min.insync.replicas = 2
}
# Location Updates
location.updates.${region} = {
partitions = 200,
replication.factor = 3,
min.insync.replicas = 2
}
# DPI Data
dpi.data.${region}.${window} = {
partitions = 100,
replication.factor = 3,
min.insync.replicas = 2
}
Data Flow Architecture
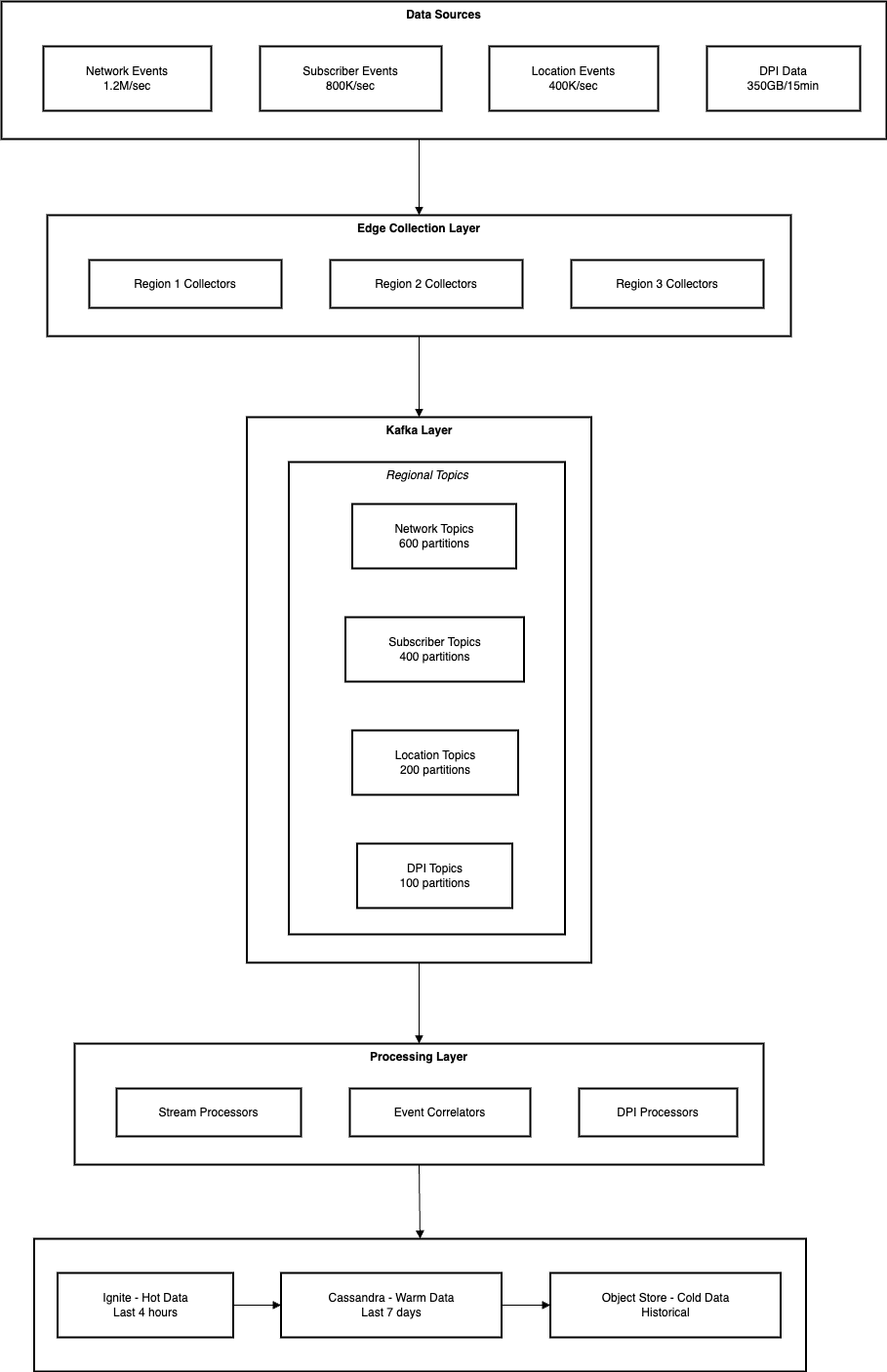
Ingestion Layer
-
Edge Collection
- Regional collectors
- Protocol handlers
- Initial validation
- Load balancing
-
Message Queuing
- Topic partitioning
- Message routing
- Back-pressure handling
- Failure detection
Processing Layer
-
Stream Processing
- Parallel execution
- State management
- Window operations
- Event correlation
-
Batch Processing
- DPI data handling
- Aggregation jobs
- Historical analysis
- Data enrichment
Storage Layer
-
Hot Storage (Ignite)
- In-memory data grid
- Affinity colocation
- Partition awareness
- Cache coherency
-
Warm Storage (Cassandra)
- Time-series optimization
- Partition strategy
- Compaction policy
- Replication design
Implementation Patterns
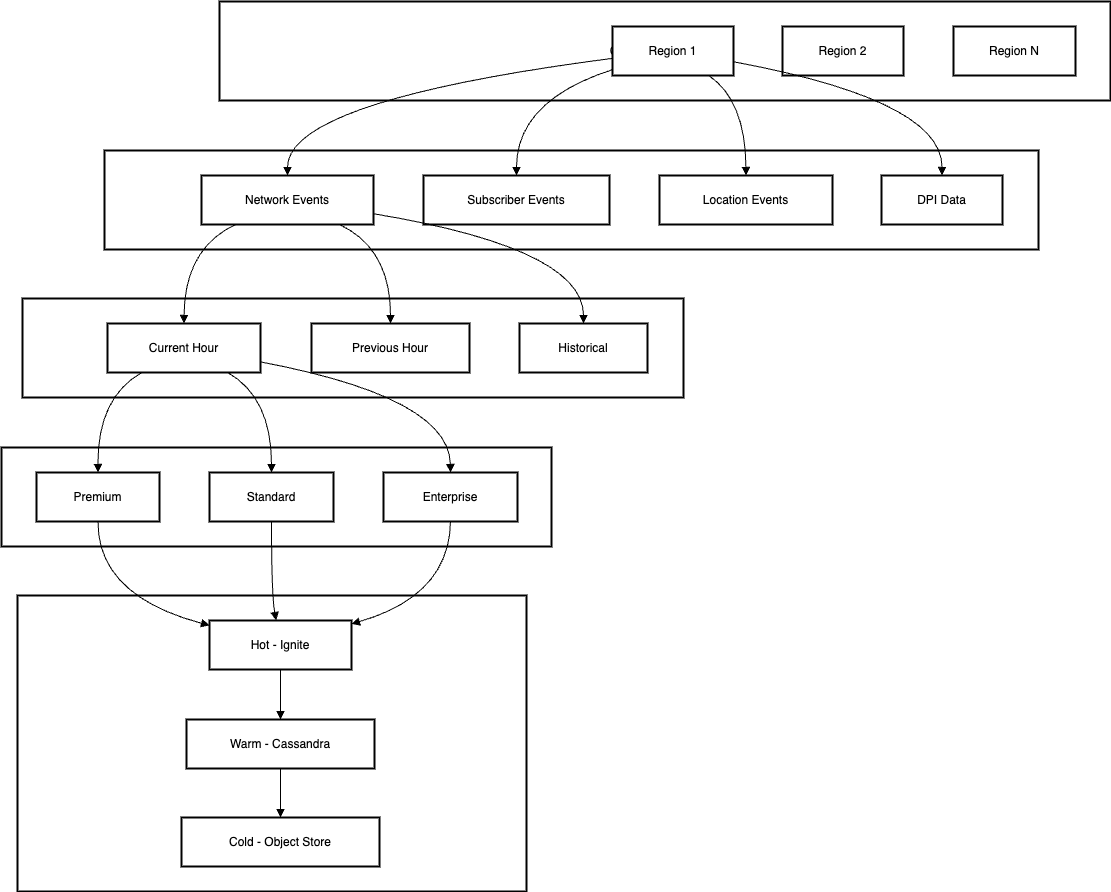
Partition Key Design
public class PartitionKeyGenerator {
public String generateKey(Event event) {
return String.format("%s:%s:%s:%s",
event.getRegion(),
event.getType(),
event.getTimeWindow(),
event.getSegment());
}
public String generateDPIKey(DPIRecord record) {
return String.format("%s:%s:%d",
record.getRegion(),
record.getProtocol(),
record.getTimeWindow().getEpochSecond());
}
}
Data Flow Control
@Component
public class DataFlowManager {
private final KafkaTemplate<String, Event> kafkaTemplate;
private final IgniteCache<String, ProcessedEvent> eventCache;
private final CassandraTemplate cassandraTemplate;
public void routeEvent(Event event) {
String partitionKey = keyGenerator.generateKey(event);
String topic = determineTopicName(event);
kafkaTemplate.send(topic, partitionKey, event)
.addCallback(this::handleSuccess, this::handleError);
}
private String determineTopicName(Event event) {
return String.format("%s.events.%s.%s",
event.getType().toLowerCase(),
event.getRegion().toLowerCase(),
event.getCategory().toLowerCase());
}
}
Performance Optimization
Partition Balancing
-
Static Balancing
- Even partition distribution
- Geographic alignment
- Resource allocation
- Network topology awareness
-
Dynamic Balancing
- Load monitoring
- Auto-rebalancing
- Hotspot detection
- Traffic shifting
Flow Control
-
Back-pressure Handling
- Buffer management
- Rate limiting
- Drop policies
- Recovery procedures
-
Resource Management
- Thread pool tuning
- Memory allocation
- Network buffers
- Disk I/O optimization
Monitoring and Maintenance
Key Metrics
-
Partition Metrics
- Size distribution
- Event distribution
- Processing latency
- Replication lag
-
Flow Metrics
- Throughput rates
- Queue depths
- Error rates
- Resource utilization
Maintenance Procedures
-
Partition Management
- Regular rebalancing
- Cleanup operations
- Performance tuning
- Capacity planning
-
Flow Optimization
- Bottleneck identification
- Resource adjustment
- Configuration tuning
- Performance testing
Lessons Learned
-
Partition Design
- Start with more partitions than needed
- Consider future growth
- Monitor partition balance
- Plan for rebalancing
-
Flow Management
- Implement back-pressure early
- Monitor flow rates closely
- Plan for failure scenarios
- Test at scale
-
Performance Tuning
- Regular monitoring essential
- Proactive optimization
- Capacity planning
- Documentation important
Looking Ahead
In Part 3, we’ll explore how we managed memory with Apache Ignite to handle this massive scale of data processing efficiently. We’ll dive into memory architecture, tiered storage, eviction policies, and performance optimization techniques.
Stay tuned to learn how we achieved sub-millisecond response times while processing millions of events per second.