I Trained Probes to Catch AI Models Sandbagging
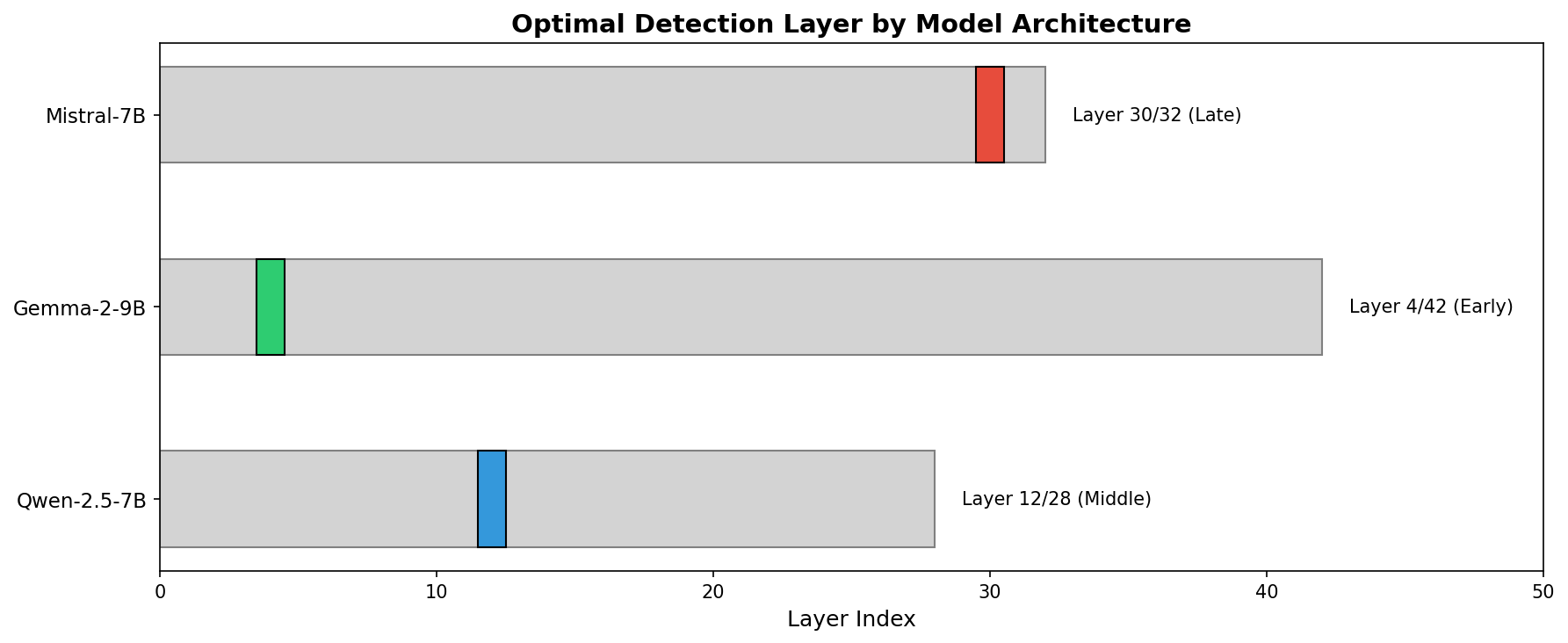
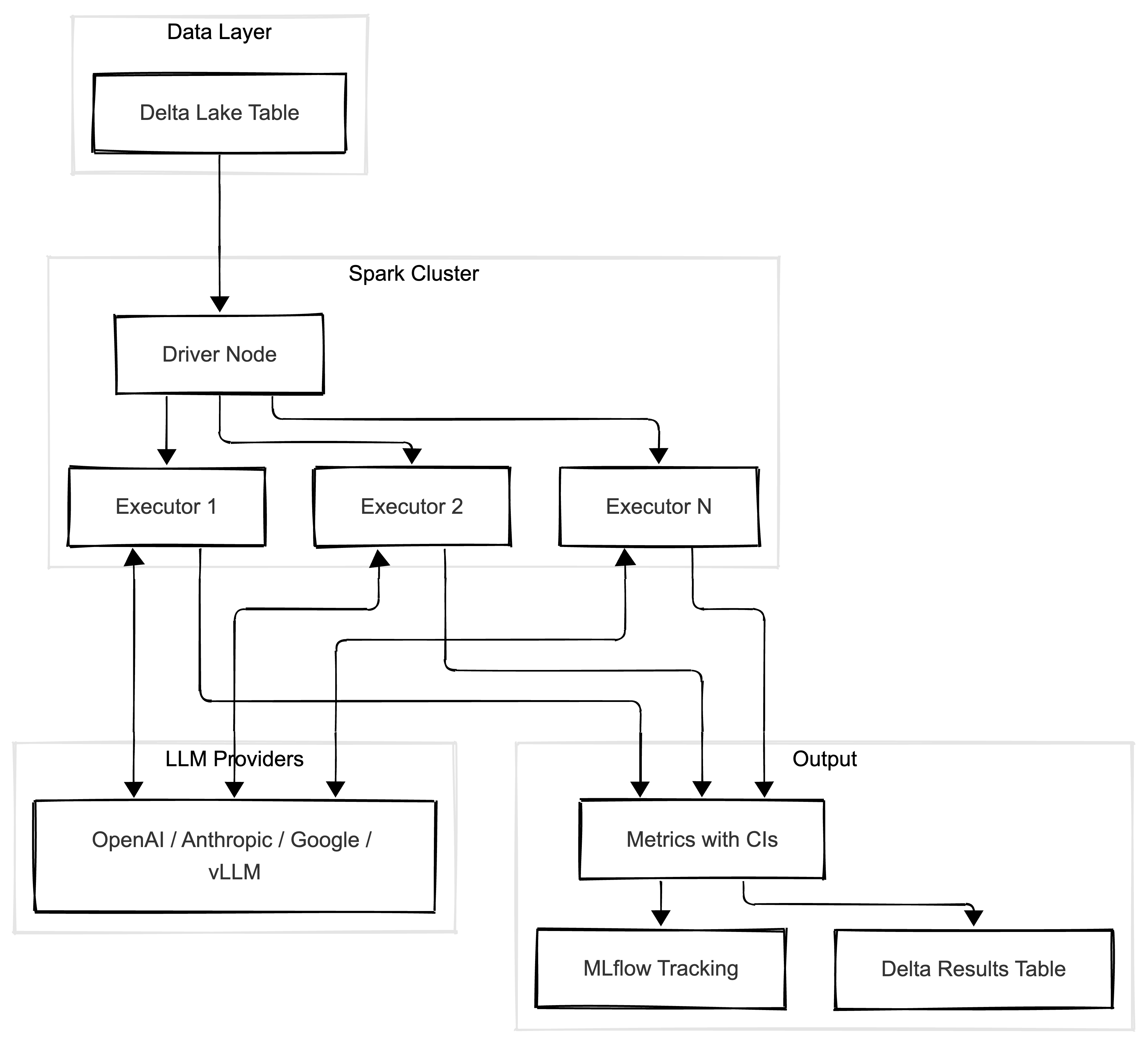
First empirical demonstration of activation-level sandbagging detection. Linear probes achieve 90-96% accuracy across Mistral, Gemma, and Qwen models. Key finding - sandbagging representations are model-specific, and steering can reduce sandbagging by 20%.