TL;DR
The Problem: AI has no consent layer. Creators can’t control how their data is used for training. Users can’t take their AI profiles between systems. Agents have unrestricted access with no permission framework. I wrote four open standards (LLMConsent) to fix this - think HTTP for AI consent. They’re on GitHub , they need work, and I need your help building them. This isn’t a product pitch, it’s an RFC.
Look, every major AI company is getting sued right now. The New York Times is suing OpenAI. Getty Images is suing Stability AI. Thousands of authors, artists, and photographers have lawsuits going. And honestly? They have a point.
But here’s what frustrates me: there’s no technical standard for any of this. No way for a creator to say “yes, you can train on my work, but only for these specific purposes, and I want attribution.” No protocol for documenting consent, tracking usage, or compensating creators.
And it’s not just training data. Your AI assistant can book flights and send emails on your behalf right now. But can it also wire money? Delete all your files? Post on social media pretending to be you? There’s no standard permission framework. Every company is just winging it.
I think the solution is obvious: AI needs what the internet had in the 1980s. Open standards that anyone can implement. Not a product you have to buy. Not a platform you have to trust. A protocol.
So I wrote some specs. Four of them, actually. They’re called LLMConsent, and they’re all on GitHub. But here’s the thing - I can’t build this alone. This needs to work like HTTP or TCP/IP: documented standards, open governance, rough consensus, no single owner.
This post is basically an RFC. I want your feedback. I want you to poke holes in it. And if you think it’s useful, I want your help building it.
The Three Problems We’re Not Solving
Problem 1: Training Data is a Legal Minefield
Right now, if you’re a writer and you want AI companies to train on your work, but only non-commercially, with attribution, and for fair compensation… you can’t actually express that anywhere. There’s no standard format. No technical mechanism.
Your only options are:
- Put it online and hope companies respect robots.txt (they don’t)
- Keep it completely private (so no one can use it)
- Sue after the fact (expensive, slow, everyone loses)
This is insane. We have MIME types for file formats. We have Creative Commons for content licensing. We have OAuth for API access. But for AI training data? Nothing.
Problem 2: AI Agents Have Root Access
Your email agent can send emails. That’s useful. But right now, most agent frameworks give the LLM direct access to your email API with your credentials. Which means if the LLM gets confused (or exploited through prompt injection), it can:
- Email your entire contact list
- Delete all your emails
- Impersonate you to your boss
- Forward confidential information to anyone
We wouldn’t give a bash script unrestricted sudo access. Why are we giving AI agents unrestricted API access?
There’s no standard way to say: “This agent can send emails, but only to people at my company, and max 10 per day, and it can draft messages but a human has to approve them before they’re sent.”
Problem 3: Context Dies When You Switch Systems
You’ve had hundreds of conversations with ChatGPT. It knows your writing style, your preferences, your context. That data is incredibly valuable - it’s why ChatGPT’s responses feel personalized to you.
But you don’t own any of it. You can’t export it. You can’t take it to Claude or Gemini. Every time you switch AI systems, you start from scratch. Even worse - when you talk to one AI agent and then ask another for help, they can’t share context. You have to re-explain everything.
Imagine if your browser history, bookmarks, and cookies were locked to Chrome and you couldn’t export them to Firefox. That’s where we are with AI.
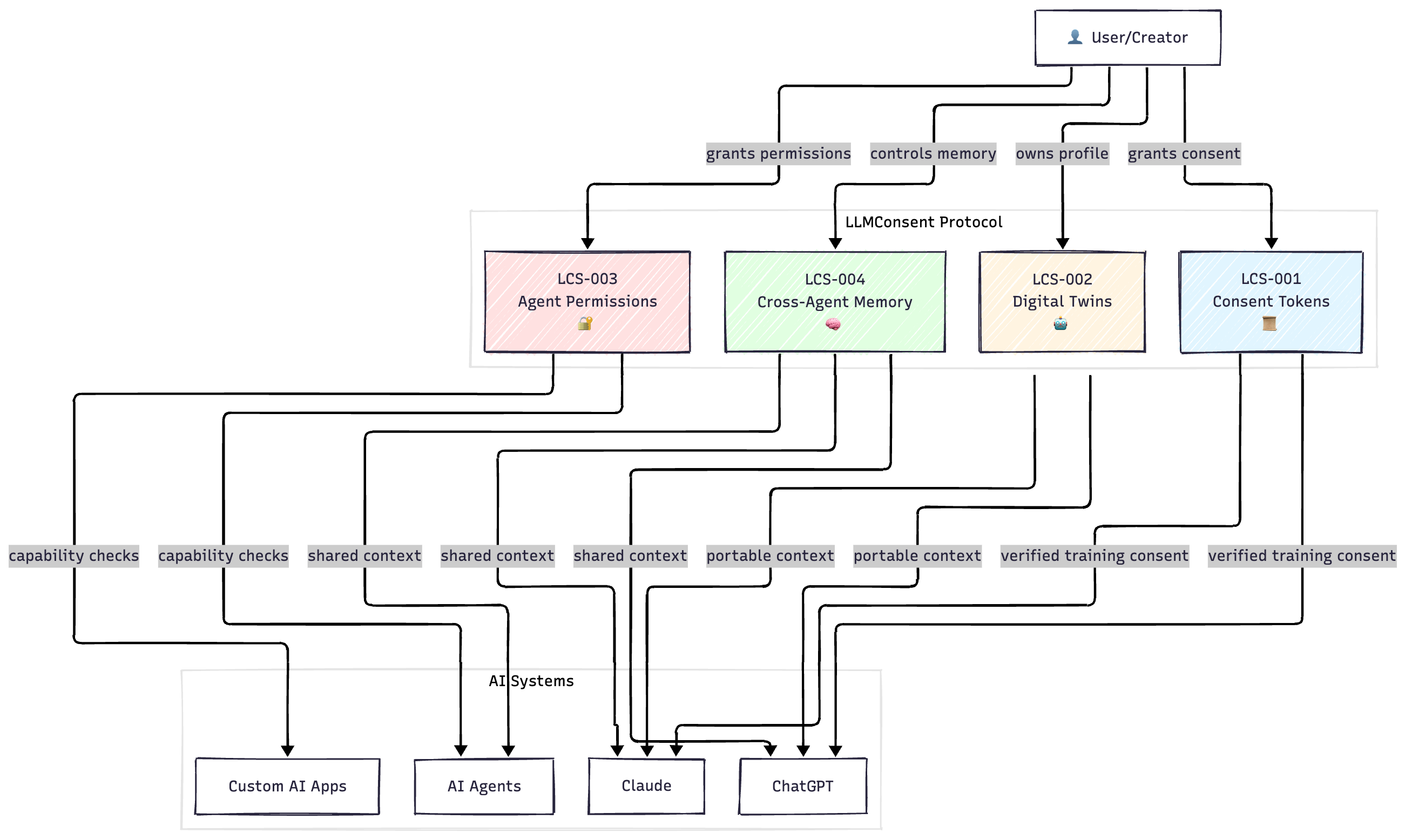
These aren’t three separate problems. They’re all the same problem: AI has no consent layer.
What Would a Consent Protocol Look Like?
I spent the last few months trying to figure this out. I kept coming back to a few core principles:
-
It has to be decentralized. If OpenAI controls the protocol, Meta won’t use it. If the US government mandates it, it won’t work in China. It needs to be like DNS or BGP - no single owner.
-
It has to be cryptographically verifiable. You can’t just trust that consent was given. You need to be able to prove it mathematically.
-
It has to be economically sustainable. Lawsuits aren’t sustainable. Micropayments might be.
-
It has to be open source. If people can’t read the spec, they can’t trust it or build on it.
So I wrote four standards. They’re all documented on GitHub. None of them are perfect. But at least they’re something concrete to discuss.
LCS-001: Consent Tokens (The Foundation)
Read the full LCS-001 Standards
This is the basic building block. It’s a standard data structure for expressing consent to use your data.
Think of it like a software license file, but machine-readable and cryptographically signed:
{
dataHash: "0xabc123...", // unique identifier for your data
owner: "0x742d35Cc...", // your wallet address
permissions: 5, // Bitmask: TRAIN=1, INFER=2, AGENT=4, MEMORY=8
modelIds: ["gpt-5", "claude-4"], // which models can use this
validUntil: "2026-01-01", // time-bounded
trainingRate: "0.001", // payment per training epoch
inferenceRate: "0.00001", // payment per 1k tokens
revocable: true, // can be revoked anytime
unlearningEnabled: true // can request model unlearning
}
Any AI company can implement this. Any creator can issue these tokens. No middleman required.
The token lives on-chain (I’m using Ethereum L2s to keep costs low), which means:
- You can revoke it at any time
- Anyone can verify it’s authentic
- There’s a permanent record of what was consented to
- Payments can be automated through smart contracts
- You can request the model “unlearn” your data
The Hard Part: Enforcement
Here’s the thing I’m struggling with. This standard lets you express consent. But how do you enforce it?
If OpenAI trains GPT-6 on your novel without checking for a consent token, what happens? Right now, nothing. You’d still have to sue them.
I think the answer is a combination of:
- Regulatory pressure - The EU AI Act is starting to require consent documentation
- Market pressure - Users demanding to know what data trained their AI
- Economic incentives - If creators get paid through the protocol, they’ll want AI companies to use it
But I’m not going to pretend this is solved. It’s not. That’s why I need lawyers and policy people to weigh in.
LCS-002: Digital Twins (Your Portable AI Profile)
Read the full LCS-002 Standards
This one solves the “starting from scratch” problem.
The idea: you should own your AI profile. All the context about you that makes AI responses personalized - your preferences, your writing style, your domain knowledge - should be your data, stored in a format you control and can take anywhere.
{
owner: "0x742d35Cc...",
modelHash: "ipfs://Qm...", // pointer to your model
version: 3, // increments each time it updates
learningRate: 100, // how fast it adapts (basis points)
confidence: 8500, // model confidence score
// What AI systems see about you
dimensions: {
preferences: {
communication_style: "concise",
expertise_level: "advanced"
},
context: {
profession: "encrypted:0x...", // private dimension
interests: ["AI", "blockchain"]
}
},
// Privacy controls
privateDimensions: ["profession", "location"],
excludedTopics: ["health", "finances"],
// Which agents can access this
agentAccess: {
"chatgpt": "READ_PUBLIC",
"my_assistant": "READ_PRIVATE"
}
}
How it works:
- You use ChatGPT. Your conversations gradually train a small, personalized model (your “digital twin”).
- The model is stored encrypted on IPFS or Arweave. You hold the keys.
- When you switch to Claude, you import your twin. Claude can query it to understand your preferences, your context, your communication style.
- The twin evolves over time. Recent patterns get more weight. Old patterns fade without reinforcement.
- You control what each AI system can see - public dimensions vs. private ones.
Why this matters:
- No vendor lock-in. Your AI relationship is portable.
- Privacy by default. Your personal context never leaves your control.
- Solves the cold-start problem. Every new AI system doesn’t start from zero.
- Continuous learning across all your AI interactions.
Why this is hard:
- Model formats aren’t standardized yet. ChatGPT’s fine-tuned model won’t run in Claude’s infrastructure.
- Privacy-preserving inference is computationally expensive.
- Evolution protocol needs to handle contradictions gracefully (what if you tell ChatGPT one thing and Claude another?).
The spec defines how updates should work - blending new data with existing models, privacy filters, and zero-knowledge proofs that updates are valid without revealing the data. It’s aspirational in some ways, but we need to define what we’re building toward.
LCS-003: Agent Permissions (The Urgent One)
Read the full LCS-003 Standards
Okay, this one is critical and we need it now.
AI agents are already booking flights, sending emails, managing calendars, and handling customer support. And most of them have way too much access.
This standard defines capability-based security for AI agents. Here’s how it works:
{
agentId: "email_assistant_v2",
owner: "0x742d35Cc...",
allowedActions: ["READ_DATA", "WRITE_DATA", "EXTERNAL_API"],
// Hard limits
maxSpend: "0", // can't spend money
maxGasPerTx: "100000", // gas limit
rateLimit: 10, // max 10 actions per hour
allowedDomains: ["*@company.com"], // can only email internal
expiresAt: "2025-12-31",
requiresConfirmation: true, // user confirms each action
// Can this agent delegate to others?
canDelegate: true,
maxDelegationDepth: 2 // can only delegate 2 levels deep
}
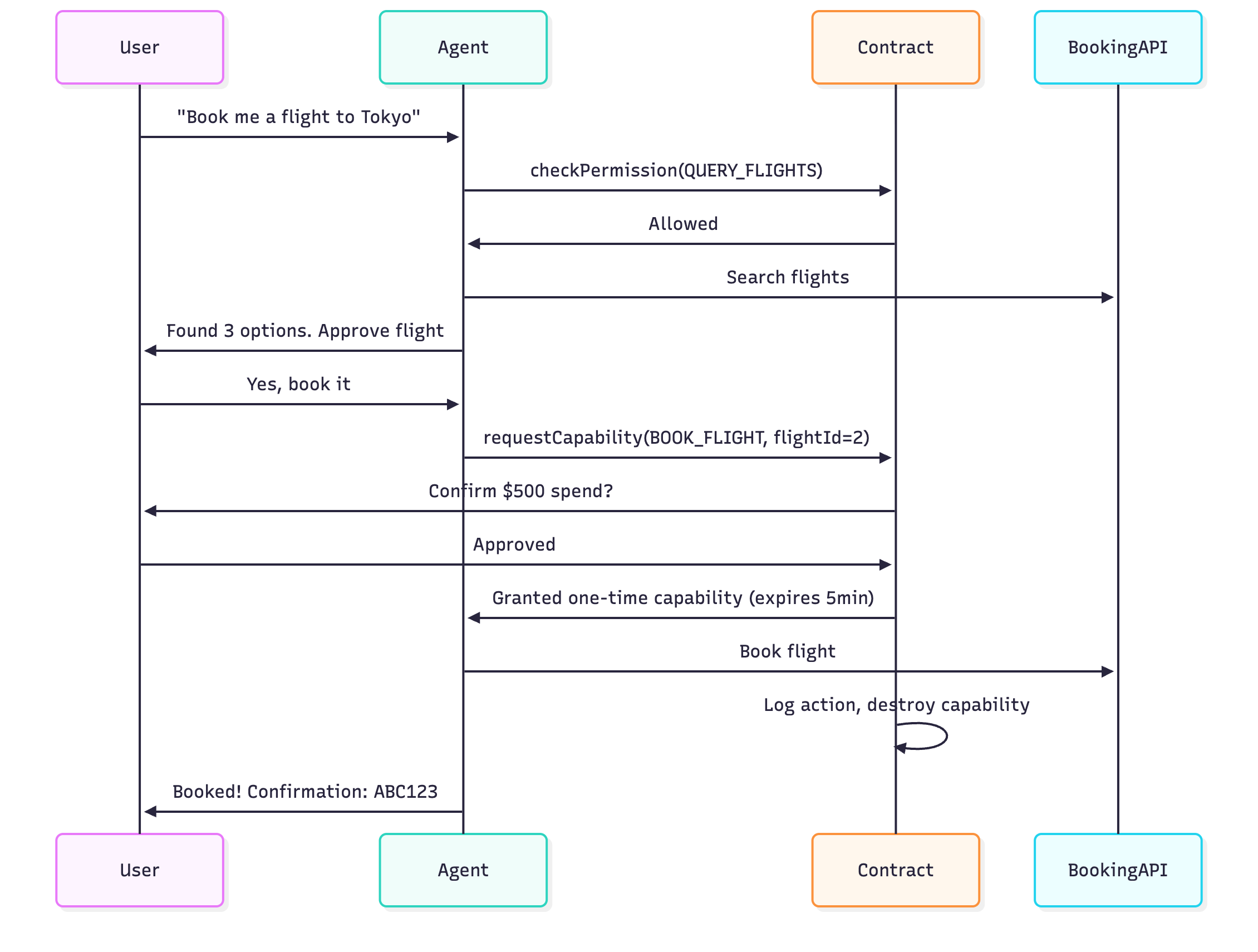
The permission flow looks like this:
Why this works:
Even if the agent gets compromised through prompt injection, it can only use the specific capabilities it was granted. It can’t:
- Book a different flight
- Spend more than approved
- Use the capability after it expires
- Delegate capabilities it doesn’t have
Advanced features in the spec:
- Delegation chains: Your main assistant can delegate to a specialist agent, but the specialist has a subset of permissions and can’t delegate further.
- Circuit breakers: Auto-pause the agent if it exceeds spend limits or exhibits unusual behavior.
- Multi-signature: High-risk actions require multiple confirmations.
- Certification: Agents can get certified for GDPR compliance, SOC2, or other standards.
- Permission templates: Pre-defined sets for common agent types (trading bot, personal assistant, research agent).
Example workflow with delegation:
- You tell your primary agent: “Help me plan my trip to Tokyo.”
- Primary agent recognizes it needs specialized help. It delegates to FlightSearchAgent with permissions:
["QUERY_FLIGHTS", "READ_CALENDAR"]- but FlightSearchAgent cannot book anything. - FlightSearchAgent does research, passes results back.
- You approve a specific flight.
- Primary agent creates a one-time capability for BookingAgent: “Can book THIS SPECIFIC FLIGHT. Capability expires in 5 minutes.”
- Flight is booked. Capability is destroyed.
This is literally just applying Unix file permissions to AI agents. Not revolutionary, just necessary.
Why this is urgent:
Agent frameworks like LangChain, AutoGPT, and CrewAI are being used in production right now. With API keys hardcoded. With unlimited access. One prompt injection away from disaster.
We need this standard implemented before the first major agent breach happens.
LCS-004: Cross-Agent Memory (The Glue)
Read the full LCS-004 Standards
Here’s something I realized while writing the other specs: even if you have a digital twin and agents with proper permissions, there’s still a gap. How do agents share context with each other?
Right now, if you ask ChatGPT to research something, then ask Claude to write about it, Claude has no idea what ChatGPT found. You have to copy-paste everything manually.
LCS-004 defines shared memory pools that agents can read from and write to, with your permission.
{
poolId: "my_work_context",
owner: "0x742d35Cc...",
memories: [
{
memoryId: "0xdef...",
type: "PREFERENCE", // or CONTEXT, KNOWLEDGE, PROCEDURE
content: {
subject: "meeting_style",
predicate: "prefers",
object: "video_off",
context: "morning_meetings"
},
confidence: 0.9,
timestamp: "2025-10-18T10:00:00Z",
createdBy: "chatgpt_agent"
}
],
// Access control
readAccess: ["chatgpt", "claude", "my_assistant"],
writeAccess: ["my_assistant"],
// Memory management
maxSize: 1000,
autoMerge: true, // merge similar memories
deduplication: true // remove duplicates
}
How it works:
- You have a conversation with ChatGPT about your preferences for technical writing.
- ChatGPT writes memories to your shared pool: “User prefers bullet points in technical discussions,” “User wants code examples,” etc.
- You switch to Claude for help writing documentation.
- Claude reads from your memory pool and already knows your preferences without you repeating them.
- Claude adds its own memories: “User’s documentation is about LLMConsent protocol.”
- Next time any agent helps you, it has all this context.
Smart features:
- Conflict resolution: If two memories contradict, the system uses recency, confidence scores, and source authority to decide which to trust.
- Importance scoring: Memories that are accessed frequently or have high confidence get kept; rarely-used memories get pruned.
- Memory types: Different types for different purposes - preferences, factual knowledge, procedures, temporal events.
- Privacy layers: Some memories are public, some are encrypted, some are ephemeral (auto-delete after use).
Why this is powerful:
Imagine you’re working on a project. You ask one agent to research competitors, another to draft a strategy, another to create a financial model. Right now, each one works in isolation.
With shared memory:
- Research agent writes findings to the pool
- Strategy agent reads those findings and adds strategic insights
- Finance agent reads both and builds a model
- All context is preserved and you didn’t have to manually pass data between them
This creates a continuous AI experience rather than fragmented conversations.
Why Blockchain? (I Know, I Know…)
Look, I get it. “Blockchain” sets off alarm bells. Most crypto projects are vaporware or scams.
But hear me out on why I think it’s the right tool here:
What we need:
- A global database of consent tokens that any AI company can query
- No single company controls it
- Anyone can verify entries are authentic
- Automatic payments when conditions are met
- Resistant to tampering or deletion
- Works across jurisdictions
What blockchain does:
- Provides a global, shared state
- No central authority
- Cryptographically verifiable
- Programmable with smart contracts
- Immutable history
- Doesn’t require trusting any one entity
I’m not trying to create a token economy or make anyone rich. I just need a neutral, global database that nobody owns.
And L2s (like Arbitrum or Base) make this cheap now. We’re talking <$0.01 per transaction. Compare that to credit card interchange fees (2-3%) or lawsuit costs (millions).
If someone has a better alternative that’s decentralized, verifiable, and doesn’t require trusting a company or government, I’m all ears. But I haven’t found one.
The Objections (And Why They Keep Me Up at Night)
“Attribution is impossible in neural networks.”
Fair. It’s really hard. Current methods (influence functions, gradient-based attribution) are computationally expensive and imperfect.
But I think we’re letting perfect be the enemy of good. Even coarse-grained attribution would be progress. And the research is advancing - papers are coming out on this regularly.
Maybe we start with document-level attribution and improve over time. Maybe we accept 80% accuracy instead of 100%. Better than the current system (0% attribution).
“AI companies will never adopt this voluntarily.”
Probably true. Why would they? It creates liability, costs money, and might limit their training data.
But I think a few things could force adoption:
- Regulation - The EU AI Act is starting to require consent documentation. Other jurisdictions will follow.
- Lawsuits - The current approach (train on everything, deal with lawsuits later) is expensive and creates PR nightmares.
- Market pressure - Users are starting to care about data provenance. “Ethically trained AI” could be a competitive advantage.
- Developer demand - Engineers building with AI want permission frameworks for agents. LCS-003 solves a real security problem.
Standards need to exist before the pressure hits. We saw this with HTTPS - SSL existed for years before browsers finally started enforcing it.
“Micropayments don’t work. Nobody wants $0.001.”
Maybe. I honestly don’t know.
But consider: Spotify pays artists fractions of a cent per stream. It’s not a lot per play, but it’s passive income that adds up. Some artists make their entire living off it.
Compare that to the current AI training model: artists get $0 unless they sue for billions (and probably lose).
Micropayments might not be perfect, but they’re better than nothing. And if we build the infrastructure, the market can figure out the right price.
“This is too complex. Users won’t understand it.”
Also probably true.
But users don’t understand HTTPS certificates or OAuth tokens either. They just click “Allow” and trust that the infrastructure works.
The goal isn’t to make every user manage consent tokens manually. The goal is to build infrastructure that tools and platforms can build on top of.
Think of it like this: You don’t interact with TCP/IP directly. But it’s the foundation that makes browsers, email, and video calls possible.
“You’re too late. The big AI companies already trained on everything.”
For training data, maybe. GPT-4, Claude, Gemini - they’re already trained. We can’t unring that bell.
But:
- Models will be retrained. GPT-5, GPT-6, Claude 4 - they’re coming. The next generation can be trained with proper consent.
- Agent permissions are forward-looking. We need this infrastructure before AI agents are ubiquitous.
- Digital twins and memory sharing are just starting. We can get this right from the beginning.
- The unlearning capability in LCS-001 might help with already-trained models.
Yes, we’re cleaning up a mess. But better to start cleaning than to let it get worse.
“What about the computational cost of all this verification?”
Good question. The specs have performance targets:
- Consent check: <100ms
- Memory query: <50ms
- Twin update: <1 second
- Permission verification: <200ms
These are achievable with proper caching and optimization. Most consent checks would be cached locally. You’re not hitting the blockchain for every inference.
What I Need From You
I can’t build this alone. I need:
If you’re a smart contract developer:
- Help implement these standards on-chain
- The Solidity code needs to be written, audited, and battle-tested
- We need reference implementations on Ethereum, Arbitrum, and Base
If you’re an ML researcher:
- Work on attribution methods
- How do we make influence functions practical and scalable?
- What’s the minimum viable attribution that’s “good enough”?
- Help with the digital twin evolution protocols
If you work at an AI company:
- Push for adoption internally
- Even just implementing LCS-003 for agent permissions would be huge
- Talk to your legal team about consent frameworks
- Consider how your system could respect consent tokens
If you’re a lawyer or policy person:
- Tell me what I’m getting wrong
- Does this align with GDPR? The EU AI Act? California privacy laws?
- What liability issues am I not seeing?
- How do we make this regulation-proof?
If you’re building AI applications:
- Try implementing consent checks in your apps
- Give feedback on what’s missing from the specs
- Help me understand what developers actually need
- Build SDKs and tools that make this easier
If you’re just skeptical:
- That’s good. Poke holes in this.
- Where are the flaws? What am I not thinking about?
- Better to find problems now than after people depend on this
The specs are on GitHub: github.com/LLMConsent/llmconsent-standards
It’s all open source. Licensed under Creative Commons. No company owns it. No tokens to buy. Just open standards that anyone can implement.
Why I’m Doing This
Honestly? Because I’m worried.
I think we’re at a critical moment. AI is moving fast - faster than regulation, faster than ethics discussions, faster than technical standards.
And I see two possible futures:
Future 1: A few big companies control everything. Your data, your AI profiles, your agent permissions - all locked into proprietary systems. No interoperability. No user control. No consent framework. Just “trust us.”
Future 2: Open standards that anyone can implement. Decentralized infrastructure that no single entity controls. Users have sovereignty over their data and AI representations. Creators get compensated fairly. Agents operate with clear permission boundaries.
I want future 2. But it won’t happen by accident. It requires people building infrastructure now, while things are still fluid.
Maybe I’m wrong about the technical approach. Maybe blockchain isn’t the right tool. Maybe micropayments won’t work. Maybe attribution is unsolvable. Maybe digital twins are too complex.
But I’d rather try and fail than not try at all.
Because if we don’t build a consent layer for AI, we’ll end up with the same centralized, locked-down, surveillance-capitalism model we have for social media. And we’ll spend the next 20 years regretting it.
Let’s Build This Together
I’m not trying to create a product or start a company. I’m trying to write standards. Like Tim Berners-Lee writing the HTTP spec, or Vint Cerf designing TCP/IP.
The standards might be wrong. They probably need significant revision. That’s fine. That’s how open standards work - rough consensus through iteration.
But we need to start somewhere.
So here’s my ask: read the specs. Break them. Tell me what’s wrong. And if you think there’s something here worth building, help me build it.
Join the GitHub discussions. Open issues. Submit proposals. Write code. Whatever your skills are, there’s work to be done.
Because AI is too important to be built without consent. And consent is too important to be controlled by any single entity.
Let’s build the consent layer together.
Links:
- Standards: github.com/LLMConsent/llmconsent-standards
- Website: llmconsent.org
- Discord: discord.gg/c2tjrZKcbR
- My email: [email protected]
I’d love to hear from you.