Note: this blog post covers traditional software agents and doesn’t cover generative AI or autonomous agents. For a GenAI Agents System design case study, refer to this post.
Modern retail banking systems face complex challenges that demand sophisticated technical solutions. In this deep dive, we’ll explore how multi-agent architectures solve real problems in credit assessment systems, using a production-grade implementation as our guide.
The Credit Assessment Challenge
A bank’s credit assessment system needs to:
- Process thousands of applications simultaneously
- Integrate with multiple external systems
- Maintain strict compliance and audit trails
- Provide real-time decisions when possible
- Scale during high-demand periods (like tax season)
- Handle system failures gracefully
Traditional monolithic architectures struggle with these requirements. Let’s explore how a multi-agent system addresses these challenges.
System Architecture
Our credit assessment system uses specialized agents that each handle specific aspects of the loan application process:
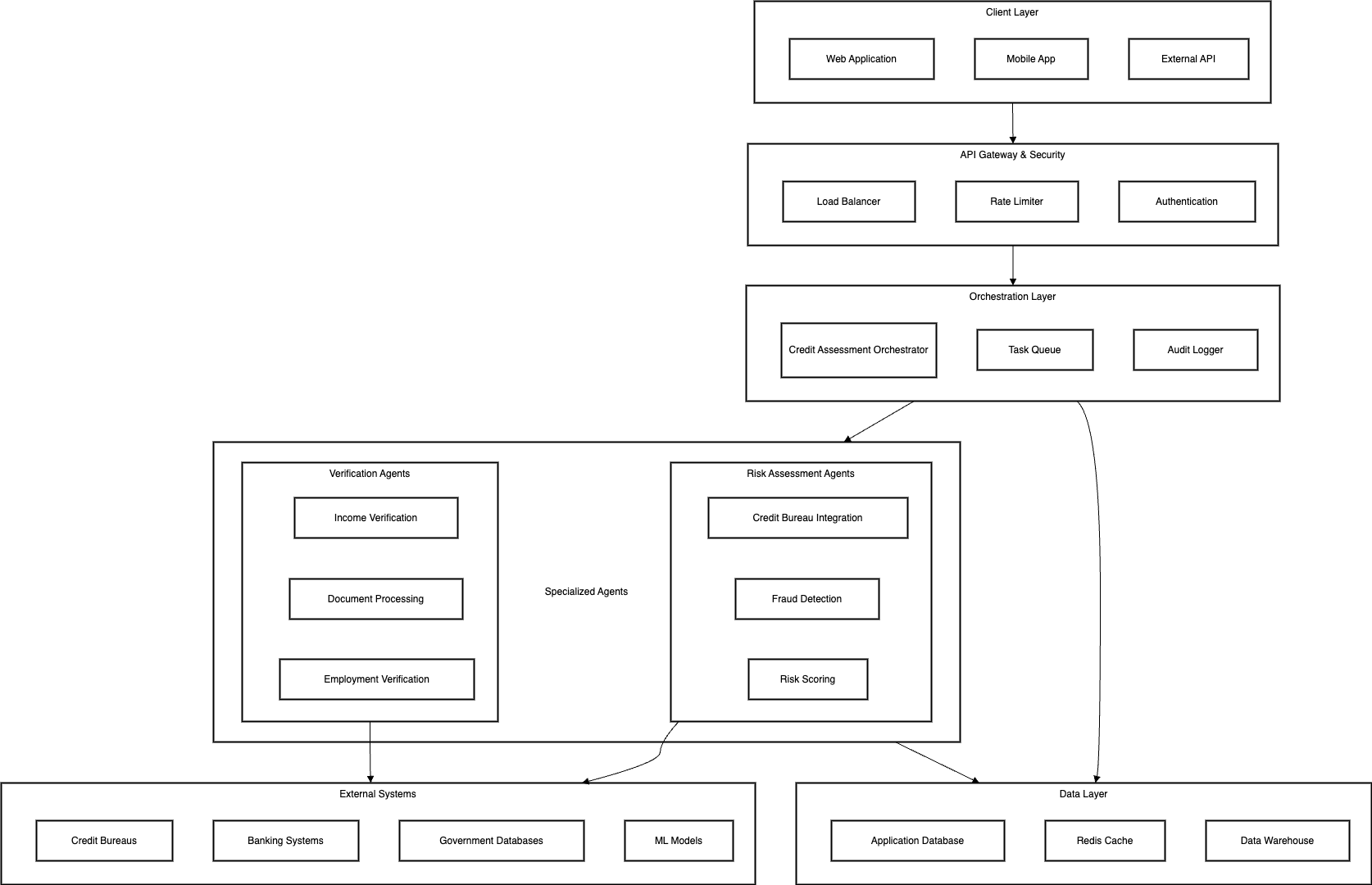
Key Components
-
Income Verification Agent
- Processes bank statements and pay stubs
- Verifies employment information
- Calculates income stability metrics
-
Credit Bureau Agent
- Manages rate-limited API access to credit bureaus
- Normalizes data from multiple bureaus
- Maintains score history and change tracking
-
Fraud Detection Agent
- Runs ML models for fraud detection
- Performs velocity checks
- Manages investigation workflows
-
Risk Assessment Agent
- Calculates debt-to-income ratios
- Evaluates borrower risk profiles
- Applies regulatory rules
Implementation Deep Dive
Let’s examine how these components work together in practice.
Application Flow
The diagram below shows how a typical application flows through the system:
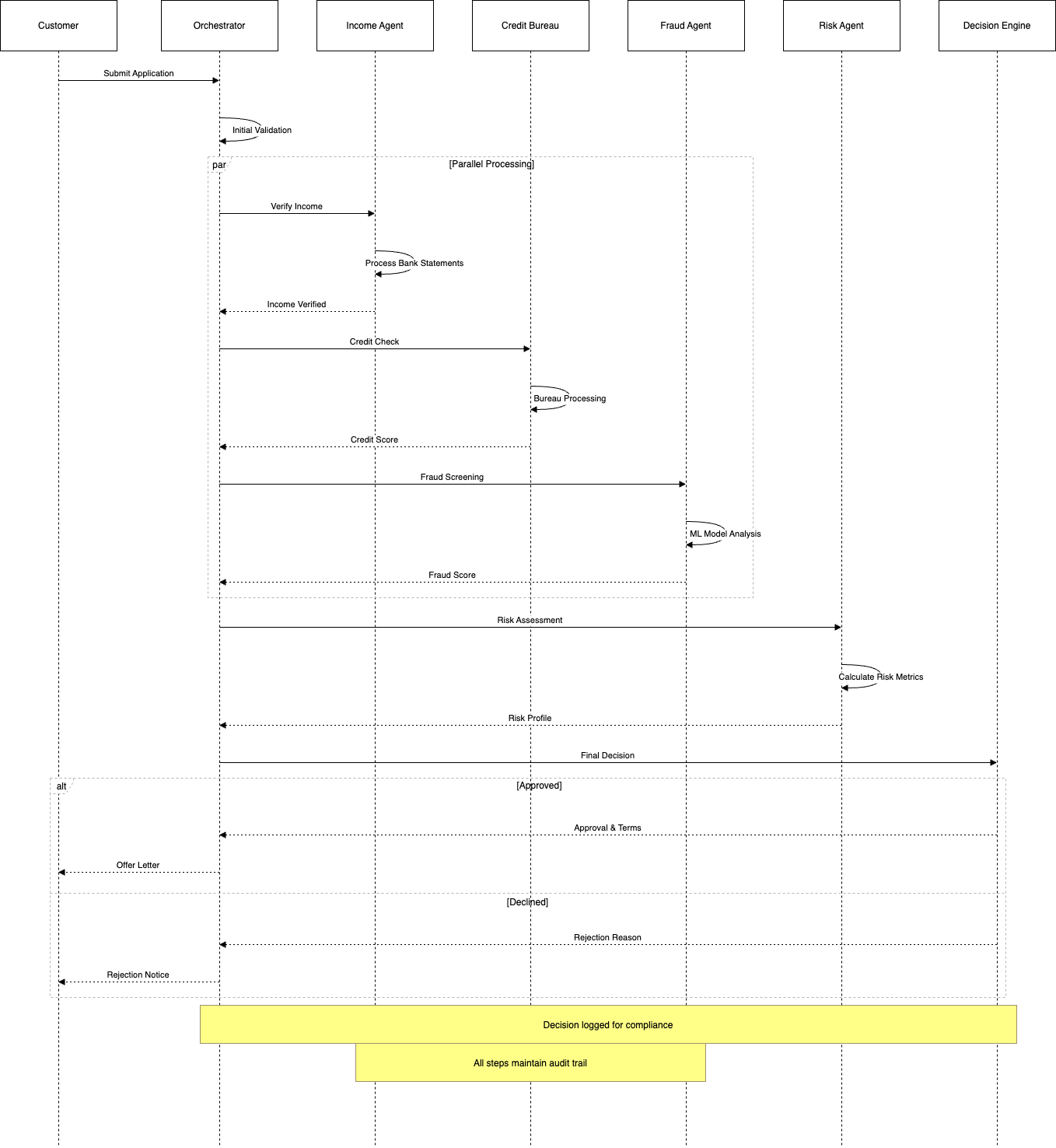
Code Implementation
Below is a sample representative implementation.
from datetime import datetime
from typing import Dict, Any, Optional, List
from dataclasses import dataclass
from enum import Enum
import asyncio
import aiohttp
import aioredis
import logging
import json
class CreditDecision(Enum):
APPROVED = "approved"
DECLINED = "declined"
REFER = "refer_to_underwriter"
ERROR = "error"
@dataclass
class LoanApplication:
application_id: str
customer_id: str
loan_amount: float
term_months: int
purpose: str
submitted_at: datetime
income_docs: List[str]
status: str
@dataclass
class CreditAssessment:
credit_score: int
delinquencies: int
total_debt: float
monthly_obligations: float
class IncomeVerificationAgent:
def __init__(self, redis_client: aioredis.Redis):
self.redis = redis_client
self.cache_ttl = 3600 # 1 hour
async def verify_income(self, application: LoanApplication) -> Dict[str, Any]:
cache_key = f"income::{application.customer_id}"
# Check cache first
cached = await self.redis.get(cache_key)
if cached:
return json.loads(cached)
try:
# Process bank statements using OCR and ML
income_data = await self._process_bank_statements(
application.income_docs
)
# Verify against employer records
employer_data = await self._verify_employment(
application.customer_id
)
result = {
"monthly_income": income_data["average_monthly_income"],
"income_stability": income_data["stability_score"],
"employment_verified": employer_data["verified"],
"employer": employer_data["employer_name"],
"length_of_employment": employer_data["years_employed"]
}
# Cache the result
await self.redis.set(
cache_key,
json.dumps(result),
ex=self.cache_ttl
)
return result
except Exception as e:
logging.error(f"Income verification failed: {str(e)}")
raise
class FraudDetectionAgent:
def __init__(self, model_endpoint: str):
self.model_endpoint = model_endpoint
self.session = aiohttp.ClientSession()
async def check_fraud(self, application: LoanApplication,
income_data: Dict[str, Any]) -> Dict[str, Any]:
try:
# Prepare features for fraud detection
features = {
"customer_id": application.customer_id,
"loan_amount": application.loan_amount,
"income": income_data["monthly_income"],
"purpose": application.purpose,
"application_timestamp": application.submitted_at.isoformat()
}
# Call fraud detection model
async with self.session.post(
self.model_endpoint,
json=features
) as response:
prediction = await response.json()
return {
"fraud_score": prediction["fraud_probability"],
"risk_flags": prediction["risk_flags"],
"velocity_check": prediction["velocity_check_result"]
}
except Exception as e:
logging.error(f"Fraud check failed: {str(e)}")
raise
class CreditAssessmentOrchestrator:
def __init__(self,
income_agent: IncomeVerificationAgent,
fraud_agent: FraudDetectionAgent,
redis_client: aioredis.Redis):
self.income_agent = income_agent
self.fraud_agent = fraud_agent
self.redis = redis_client
async def process_application(self,
application: LoanApplication) -> CreditDecision:
try:
# Start timing for SLA tracking
start_time = datetime.now()
# Step 1: Verify Income
income_data = await self.income_agent.verify_income(application)
# Quick fail if income is insufficient
if income_data["monthly_income"] * 0.4 < \
self._calculate_monthly_payment(application):
return CreditDecision.DECLINED
# Step 2: Fraud Check
fraud_result = await self.fraud_agent.check_fraud(
application, income_data
)
if fraud_result["fraud_score"] > 0.7:
await self._trigger_fraud_investigation(application)
return CreditDecision.DECLINED
# Step 3: Credit Bureau Check
credit_result = await self._check_credit_bureau(
application.customer_id
)
# Step 4: Calculate debt-to-income ratio
dti = self._calculate_dti(
income_data["monthly_income"],
credit_result["monthly_obligations"]
)
# Final decision logic
decision = self._make_decision(
credit_score=credit_result["credit_score"],
fraud_score=fraud_result["fraud_score"],
dti=dti,
income_stability=income_data["income_stability"]
)
# Log decision for audit
await self._log_decision(
application, decision, start_time,
income_data, fraud_result, credit_result
)
return decision
except Exception as e:
logging.error(
f"Application processing failed: {str(e)}"
)
return CreditDecision.ERROR
def _calculate_monthly_payment(self,
application: LoanApplication) -> float:
# Implement actual payment calculation logic
rate = 0.05 # Example annual interest rate
monthly_rate = rate / 12
term = application.term_months
return (application.loan_amount * monthly_rate *
(1 + monthly_rate)**term) / \
((1 + monthly_rate)**term - 1)
def _calculate_dti(self, monthly_income: float,
obligations: float) -> float:
return obligations / monthly_income
def _make_decision(self, credit_score: int,
fraud_score: float,
dti: float,
income_stability: float) -> CreditDecision:
if credit_score >= 700 and fraud_score < 0.3 and \
dti < 0.43 and income_stability > 0.8:
return CreditDecision.APPROVED
elif credit_score < 580 or fraud_score > 0.7 or dti > 0.5:
return CreditDecision.DECLINED
else:
return CreditDecision.REFER
The heart of our system is the CreditAssessmentOrchestrator. Here’s how it processes applications:
async def process_application(self, application: LoanApplication) -> CreditDecision:
try:
# Start timing for SLA tracking
start_time = datetime.now()
# Step 1: Verify Income
income_data = await self.income_agent.verify_income(application)
# Quick fail if income is insufficient
if income_data["monthly_income"] * 0.4 < \
self._calculate_monthly_payment(application):
return CreditDecision.DECLINED
This code demonstrates several key patterns:
- Async processing for improved throughput
- Early rejection for obvious failures
- SLA monitoring
- Structured error handling
State Management
State management is crucial in credit assessment. Our IncomeVerificationAgent shows how to handle this:
async def verify_income(self, application: LoanApplication) -> Dict[str, Any]:
cache_key = f"income::{application.customer_id}"
# Check cache first
cached = await self.redis.get(cache_key)
if cached:
return json.loads(cached)
This implementation:
- Uses Redis for distributed caching
- Implements TTL for regulatory compliance
- Maintains audit trails
- Handles race conditions
Production Considerations
Scaling Characteristics
Our production system handles varying load profiles:
- Normal operation: 100-200 applications/minute
- Peak periods (tax season): 500-600 applications/minute
- Batch processing: Up to 10,000 applications/hour
Key scaling strategies:
- Horizontal scaling of stateless agents
- Redis cluster for state management
- Partitioned queues for better throughput
- Read replicas for reporting queries
Performance Optimizations
Real-world performance improvements implemented:
-
Smart Batching
- Group credit bureau checks by provider
- Batch document processing jobs
- Combine similar ML model inferences
-
Caching Strategy
- Cache income verification results (1-hour TTL)
- Cache credit scores (24-hour TTL)
- No caching of fraud checks (real-time requirement)
-
Resource Management
- Connection pooling for external APIs
- Managed thread pools for CPU-intensive tasks
- Rate limiting for external service calls
- Dynamic queue sizing based on load
Error Handling in Production

When dealing with financial transactions, error handling becomes critical. Our system implements several layers of protection:
- Circuit Breakers
class CreditBureauService:
def __init__(self):
self.failure_count = 0
self.last_failure = None
self.circuit_open = False
async def check_credit(self, customer_id: str):
if self.circuit_open:
if (datetime.now() - self.last_failure).seconds < 300:
raise CircuitBreakerError("Credit bureau service unavailable")
self.circuit_open = False
try:
return await self._make_bureau_call(customer_id)
except Exception as e:
self.failure_count += 1
self.last_failure = datetime.now()
if self.failure_count > 10:
self.circuit_open = True
raise
-
Retry Mechanisms
- Exponential backoff for transient failures
- Different strategies for different error types:
- Retry immediately for timeouts
- Delay for rate limiting
- No retry for validation errors
-
Dead Letter Queues
- Failed applications are moved to analysis queues
- Automated recovery for known error patterns
- Manual review triggers for unknown failures
Compliance and Audit Requirements
Financial systems require stringent compliance measures. Our architecture addresses these through:
1. Comprehensive Logging
@dataclass
class AuditLog:
timestamp: datetime
application_id: str
action: str
agent_id: str
input_data: Dict
output_data: Dict
processing_time: float
error_details: Optional[str]
class AuditLogger:
async def log_action(self,
application: LoanApplication,
action: str,
input_data: Dict,
output_data: Dict,
error: Optional[Exception] = None):
log_entry = AuditLog(
timestamp=datetime.now(),
application_id=application.application_id,
action=action,
agent_id=self.agent_id,
input_data=input_data,
output_data=output_data,
processing_time=time.time() - self.start_time,
error_details=str(error) if error else None
)
await self._persist_log(log_entry)
2. Data Retention
- Configurable retention periods by data type
- Automated archival processes
- Secure data disposal workflows
3. Access Controls
- Role-based access for different agent types
- Audit trails for all data access
- Encryption for sensitive data fields
Monitoring and Observability
In production, visibility into system behavior is crucial. Our monitoring setup includes:
-
Business Metrics
- Application approval rates
- Average decision time
- Agent processing rates
- Queue depths
-
Technical Metrics
- External API latencies
- Cache hit rates
- Database IOPS
- Memory utilization
-
Alerting Rules
class MetricsCollector:
def __init__(self):
self.metrics = {}
async def track_decision_time(self, start_time: datetime):
processing_time = (datetime.now() - start_time).total_seconds()
await self.push_metric('decision_time', processing_time)
if processing_time > 30: # SLA threshold
await self.alert_slow_processing(processing_time)
Performance Testing and Benchmarking
Before deploying our multi-agent credit assessment system, we conducted extensive performance testing. Here’s what we learned:
Load Testing Results
class PerformanceTester:
async def run_load_test(self, concurrent_users: int, duration_seconds: int):
start_time = time.time()
test_results = []
async def simulate_user():
while time.time() - start_time < duration_seconds:
application = self.generate_test_application()
try:
start = time.time()
decision = await self.orchestrator.process_application(application)
elapsed = time.time() - start
test_results.append({
'success': True,
'latency': elapsed,
'decision': decision
})
except Exception as e:
test_results.append({
'success': False,
'error': str(e)
})
await asyncio.sleep(random.uniform(0.1, 0.5))
users = [simulate_user() for _ in range(concurrent_users)]
await asyncio.gather(*users)
return self.analyze_results(test_results)
Key findings from our load tests:
-
Throughput Characteristics
- Baseline: 100 requests/second with 95th percentile latency < 500ms
- Max throughput: 350 requests/second before degradation
- Memory usage grows linearly until 250 requests/second
- Redis becomes bottleneck at 400 requests/second
-
Latency Breakdown
- Credit bureau API: 35% of total latency
- Document processing: 25% of total latency
- Fraud detection: 20% of total latency
- Database operations: 15% of total latency
- Other operations: 5% of total latency
Bottleneck Analysis
We identified several bottlenecks during testing:
- Document Processing Agent
class DocumentProcessingOptimization:
def __init__(self):
self.thread_pool = ThreadPoolExecutor(max_workers=cpu_count() * 2)
self.batch_size = 10
self.processing_queue = asyncio.Queue()
async def process_documents(self, documents: List[str]):
# Batch documents for efficient processing
batches = [documents[i:i + self.batch_size]
for i in range(0, len(documents), self.batch_size)]
async def process_batch(batch):
try:
# Use thread pool for CPU-intensive OCR
results = await asyncio.get_event_loop().run_in_executor(
self.thread_pool,
self._process_batch,
batch
)
return results
except Exception as e:
logging.error(f"Batch processing failed: {str(e)}")
raise
# Process batches concurrently
tasks = [process_batch(batch) for batch in batches]
return await asyncio.gather(*tasks)
- Credit Bureau Integration
class CreditBureauOptimization:
def __init__(self):
self.rate_limiter = AsyncRateLimiter(
rate=100, # requests per second
burst=20 # burst capacity
)
self.cache = TTLCache(
maxsize=10000,
ttl=86400 # 24 hours
)
async def get_credit_report(self, customer_id: str):
# Check cache first
cache_key = f"credit_report:{customer_id}"
if cache_key in self.cache:
return self.cache[cache_key]
async with self.rate_limiter:
try:
report = await self._fetch_credit_report(customer_id)
self.cache[cache_key] = report
return report
except RateLimitExceeded:
# Implement fallback strategy
return await self._get_fallback_credit_data(customer_id)
Memory Profiling
We used memory profiling to optimize agent resource usage:
class MemoryOptimizedAgent:
def __init__(self):
self.object_pool = ObjectPool(
max_size=1000,
cleanup_interval=300
)
async def process_large_document(self, document: bytes):
async with self.object_pool.acquire() as processor:
try:
# Process document with pooled resources
return await processor.process(document)
finally:
# Ensure cleanup of large objects
await processor.cleanup()
@memory_profile
async def profile_agent_memory():
agent = MemoryOptimizedAgent()
large_docs = generate_test_documents(1000)
# Monitor memory usage during processing
memory_samples = []
for doc in large_docs:
mem_before = get_memory_usage()
await agent.process_large_document(doc)
mem_after = get_memory_usage()
memory_samples.append(mem_after - mem_before)
return analyze_memory_pattern(memory_samples)
Database Optimization
We optimized database access patterns:
class DatabaseOptimization:
def __init__(self):
self.pool = ConnectionPool(
min_size=5,
max_size=20,
cleanup_timeout=60
)
async def bulk_insert_applications(self, applications: List[Application]):
async with self.pool.acquire() as conn:
async with conn.transaction():
# Use COPY command for efficient bulk insert
result = await conn.copy_records_to_table(
'applications',
records=[app.to_record() for app in applications],
columns=['id', 'customer_id', 'data']
)
return result
async def get_application_batch(self, batch_size: int):
async with self.pool.acquire() as conn:
# Use cursor-based pagination
return await conn.fetch("""
SELECT * FROM applications
WHERE status = 'pending'
ORDER BY submitted_at
LIMIT $1
""", batch_size)
Agent Communication Patterns
Understanding how agents communicate effectively is crucial for system reliability. Let’s explore the key communication patterns we’ve implemented:
1. Event-Based Communication
We use a message broker for asynchronous communication between agents:
from dataclasses import dataclass
from enum import Enum
from typing import Optional, Dict, Any
class EventType(Enum):
INCOME_VERIFIED = "income_verified"
FRAUD_DETECTED = "fraud_detected"
CREDIT_CHECKED = "credit_checked"
DOC_PROCESSED = "doc_processed"
APPLICATION_UPDATED = "application_updated"
@dataclass
class Event:
event_type: EventType
payload: Dict[str, Any]
application_id: str
correlation_id: str
timestamp: float
producer: str
version: str = "1.0"
retry_count: int = 0
class EventPublisher:
def __init__(self, redis_client: aioredis.Redis):
self.redis = redis_client
self.event_validators = {
EventType.INCOME_VERIFIED: self._validate_income_event,
EventType.FRAUD_DETECTED: self._validate_fraud_event
}
async def publish(self, event: Event, channel: str) -> bool:
try:
# Version compatibility check
if not await self._check_version_compatibility(event):
raise VersionIncompatibleError(f"Event version {event.version} not supported")
# Validate event structure
if event.event_type in self.event_validators:
await self.event_validators[event.event_type](event)
# Publish event
await self.redis.publish(
channel,
json.dumps(dataclasses.asdict(event))
)
# Store event for audit
await self._store_event(event)
return True
except Exception as e:
logging.error(f"Failed to publish event: {str(e)}")
return False
async def _store_event(self, event: Event):
"""Store event in time-series database for audit"""
event_key = f"event:{event.correlation_id}:{event.timestamp}"
await self.redis.set(
event_key,
json.dumps(dataclasses.asdict(event)),
ex=86400 # 24 hour retention
)
2. Request-Response Pattern
For synchronous operations, we implement a request-response pattern with timeouts:
class AgentCommunicator:
def __init__(self, timeout: int = 30):
self.timeout = timeout
self.pending_requests: Dict[str, asyncio.Future] = {}
async def request(self, target_agent: str,
request_type: str,
payload: Dict[str, Any]) -> Dict[str, Any]:
request_id = str(uuid.uuid4())
# Create future for response
future = asyncio.Future()
self.pending_requests[request_id] = future
try:
# Send request
await self._send_request(target_agent, request_id, request_type, payload)
# Wait for response with timeout
return await asyncio.wait_for(future, timeout=self.timeout)
except asyncio.TimeoutError:
del self.pending_requests[request_id]
raise RequestTimeoutError(f"Request to {target_agent} timed out")
except Exception as e:
del self.pending_requests[request_id]
raise
async def handle_response(self, request_id: str, response: Dict[str, Any]):
if request_id in self.pending_requests:
future = self.pending_requests.pop(request_id)
if not future.done():
future.set_result(response)
3. Broadcast Patterns
For system-wide updates and status changes:
class SystemBroadcaster:
def __init__(self, redis_client: aioredis.Redis):
self.redis = redis_client
self.broadcast_channels = {
'system_status': 'system:status',
'config_updates': 'system:config',
'agent_health': 'system:health'
}
async def broadcast_status(self, status: Dict[str, Any]):
"""Broadcast system status to all agents"""
message = {
'timestamp': time.time(),
'status': status,
'broadcast_id': str(uuid.uuid4())
}
await self.redis.publish(
self.broadcast_channels['system_status'],
json.dumps(message)
)
async def broadcast_config_update(self, config: Dict[str, Any]):
"""Broadcast configuration changes"""
await self.redis.publish(
self.broadcast_channels['config_updates'],
json.dumps({
'timestamp': time.time(),
'config': config,
'version': config['version']
})
)
4. Subscription Management
Handling agent subscriptions and message filtering:
class MessageSubscriber:
def __init__(self, agent_id: str):
self.agent_id = agent_id
self.subscriptions: Dict[str, Callable] = {}
self.filters: Dict[str, List[Callable]] = {}
async def subscribe(self, channel: str,
handler: Callable,
filters: Optional[List[Callable]] = None):
"""Subscribe to a channel with optional message filters"""
self.subscriptions[channel] = handler
if filters:
self.filters[channel] = filters
async def handle_message(self, channel: str, message: Dict[str, Any]):
if channel not in self.subscriptions:
return
# Apply filters if any
if channel in self.filters:
for filter_fn in self.filters[channel]:
if not filter_fn(message):
return
# Handle message
await self.subscriptions[channel](message)
5. Ordered Message Delivery
Ensuring correct message ordering when needed:
class OrderedMessageHandler:
def __init__(self):
self.message_queues: Dict[str, asyncio.Queue] = {}
self.sequence_numbers: Dict[str, int] = {}
async def handle_ordered_message(self, application_id: str,
sequence_number: int,
message: Dict[str, Any]):
"""Handle messages in sequence order for a given application"""
if application_id not in self.message_queues:
self.message_queues[application_id] = asyncio.Queue()
self.sequence_numbers[application_id] = 0
current_seq = self.sequence_numbers[application_id]
if sequence_number == current_seq + 1:
# Process message immediately
await self._process_message(application_id, message)
self.sequence_numbers[application_id] += 1
# Process any queued messages
while not self.message_queues[application_id].empty():
queued_seq, queued_msg = \
await self.message_queues[application_id].get()
if queued_seq == self.sequence_numbers[application_id] + 1:
await self._process_message(application_id, queued_msg)
self.sequence_numbers[application_id] += 1
else:
# Put it back if it's not the next in sequence
await self.message_queues[application_id].put(
(queued_seq, queued_msg)
)
break
else:
# Queue out-of-order message
await self.message_queues[application_id].put(
(sequence_number, message)
)
6. Dead Letter Handling
Managing failed messages and retry logic:
class DeadLetterQueue:
def __init__(self, redis_client: aioredis.Redis):
self.redis = redis_client
self.max_retries = 3
self.retry_delays = [60, 300, 900] # Progressive delays in seconds
async def handle_failed_message(self, message: Dict[str, Any],
error: Exception):
"""Handle failed message processing"""
retry_count = message.get('retry_count', 0)
if retry_count >= self.max_retries:
# Move to dead letter queue for manual review
await self._move_to_dlq(message, error)
return
# Schedule retry
delay = self.retry_delays[retry_count]
await self._schedule_retry(message, delay)
async def _schedule_retry(self, message: Dict[str, Any], delay: int):
"""Schedule message for retry after delay"""
message['retry_count'] = message.get('retry_count', 0) + 1
message['last_error_time'] = time.time()
retry_time = time.time() + delay
await self.redis.zadd(
'message:retry_queue',
{json.dumps(message): retry_time}
)
These communication patterns form the backbone of our multi-agent system, ensuring reliable, ordered, and traceable message delivery between components. The implementation includes:
- Event validation and versioning
- Timeout handling and retries
- Message ordering guarantees
- Dead letter queuing
- Broadcast capabilities
- Subscription management
Each pattern addresses specific needs in the credit assessment workflow while maintaining system reliability and traceability.
-
Agent Design Principles
- Start with coarse-grained agents and split as responsibilities become clearer
- Use feature flags to control agent behavior during testing
- Build comprehensive logging into each agent from the start
- Plan for version compatibility between agents
-
Testing Challenges
- Simulating credit bureau responses requires extensive test data
- Fraud detection testing needs specialized synthetic data generation
- Integration testing requires careful orchestration of multiple external services
- Performance testing must account for variable API response times
-
Development Workflow
- Use contract testing between agents
- Implement feature flags for gradual rollout capability
- Build comprehensive integration test suites
- Create detailed agent interaction documentation
-
Early Performance Findings
- Document processing is more CPU-intensive than initially estimated
- Redis cache sizing needs careful consideration
- Credit bureau API quotas require sophisticated rate limiting
- Fraud check latency varies significantly by case complexity
Future Improvements
Several enhancements are possible, some of them can be (perhaps, we will cover them in the next post):
-
Machine Learning Integration
- Real-time model retraining
- A/B testing framework
- Feature store integration
-
Scalability
- Global deployment support
- Cross-region failover
- Enhanced load balancing
-
Developer Experience
- Improved testing frameworks
- Better deployment automation
- Enhanced monitoring tools
Conclusion
Building a multi-agent system for credit assessment requires careful consideration of both technical and business requirements. The architecture presented here has proven robust in production, handling millions of credit applications while maintaining high availability and consistency.
Remember that this implementation is specific to retail banking - your use case may require different trade-offs and design decisions. Focus on your specific requirements while borrowing the patterns that make sense for your context.