In the telecommunications industry, the ability to process and analyze data in real-time can mean the difference between proactive customer service and missed opportunities. This blog series details our journey in building a real-time data platform capable of processing 2.5 million events per second and handling 350GB of Deep Packet Inspection (DPI) data every 15 minutes for a major telecommunications provider.
The Challenge
Our telecommunications client faced several critical challenges that pushed the boundaries of traditional data processing:
Scale Requirements
- Processing 2.5 million events per second from various sources
- Handling 350GB of DPI data every 15 minutes (~23.3GB per minute)
- Supporting millions of active subscribers
- Operating across multiple data centers
- Maintaining sub-second response times
Business Requirements
- Real-time SIM card movement detection between devices
- Location-based service delivery
- Instant campaign targeting
- Network quality monitoring
- Fraud detection and prevention
System Scale Overview
Data Sources
-
Network Events (1.2M/sec)
- Cell tower connections
- Handovers
- Signal strength measurements
- Network quality indicators
-
Subscriber Events (800K/sec)
- SIM card activations/deactivations
- Device changes
- Service subscriptions
- Usage patterns
-
Location Updates (400K/sec)
- Cell tower triangulation
- GPS data
- Movement patterns
- Location-based triggers
-
Customer Interactions (100K/sec)
- App usage
- Service requests
- Customer care interactions
- Transaction events
-
Deep Packet Inspection (DPI)
- 350GB every 15 minutes
- Protocol analysis
- Traffic patterns
- Application usage
- QoS metrics
Architecture Overview
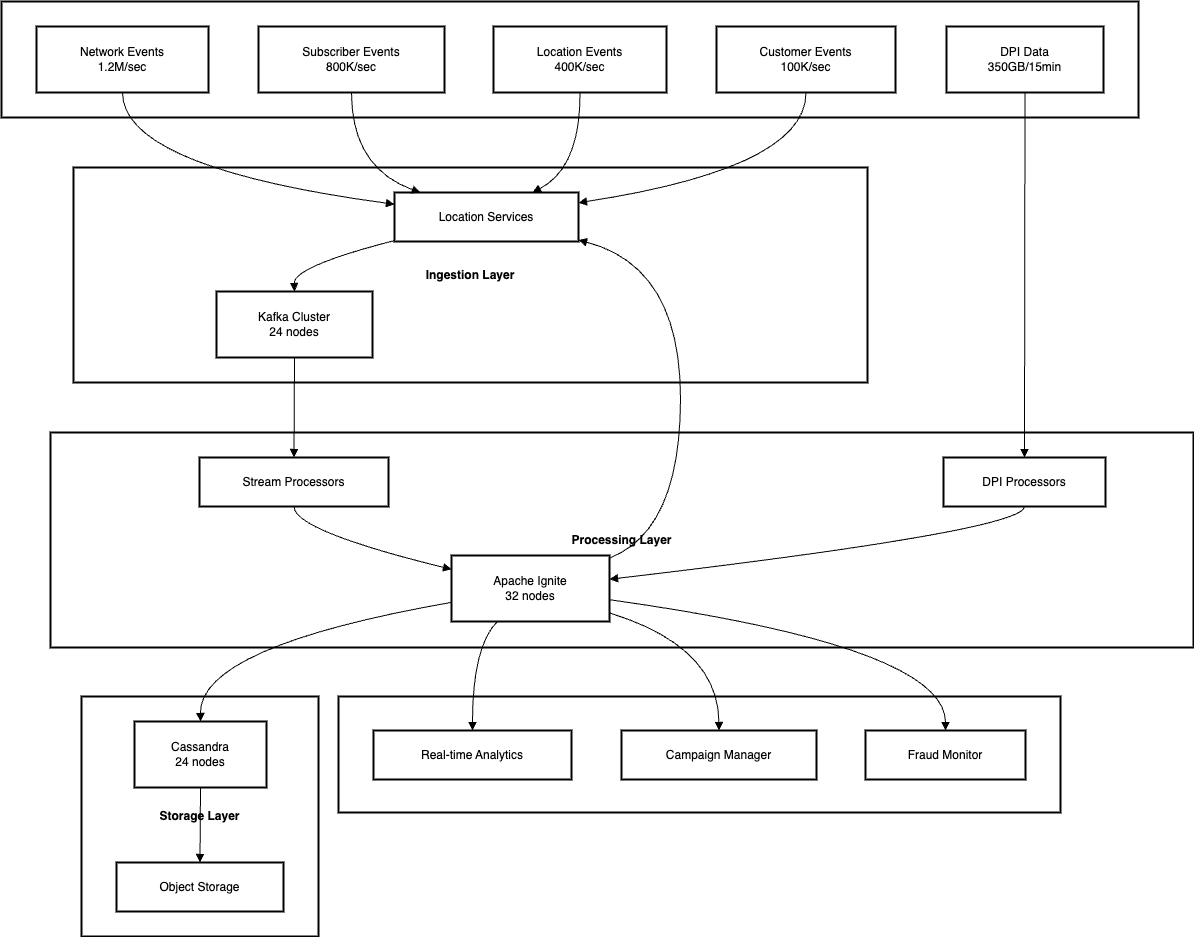
Core Components
-
Apache Kafka
- Event streaming backbone
- Message persistence
- Stream processing
- Real-time analytics
-
Apache Ignite
- In-memory computing
- Real-time processing
- Distributed caching
- ACID transactions
-
Apache Cassandra
- Long-term storage
- Time-series data
- Historical analysis
- Data archival
Infrastructure Scale
-
Kafka Cluster
- 24 broker nodes
- 3 availability zones
- 1,350+ partitions
- 25Gbps network
-
Ignite Cluster
- 32 processing nodes
- 512GB RAM per node
- NVMe storage
- NUMA-aware deployment
-
Cassandra Cluster
- 24 storage nodes
- Multi-datacenter setup
- Tiered storage
- Tuned for write-heavy workload
Key Design Decisions
1. Data Locality
- Geographic data distribution
- NUMA-aware processing
- Cache-aware scheduling
- Network topology optimization
2. State Management
- Distributed state handling
- Eventual consistency model
- State recovery mechanisms
- Cache coherency protocols
3. Performance Optimization
- Zero-copy operations
- Custom serialization
- Batch processing
- Parallel execution paths
4. Reliability
- No single point of failure
- Multi-datacenter replication
- Automatic failover
- Data consistency guarantees
System Interaction Flow
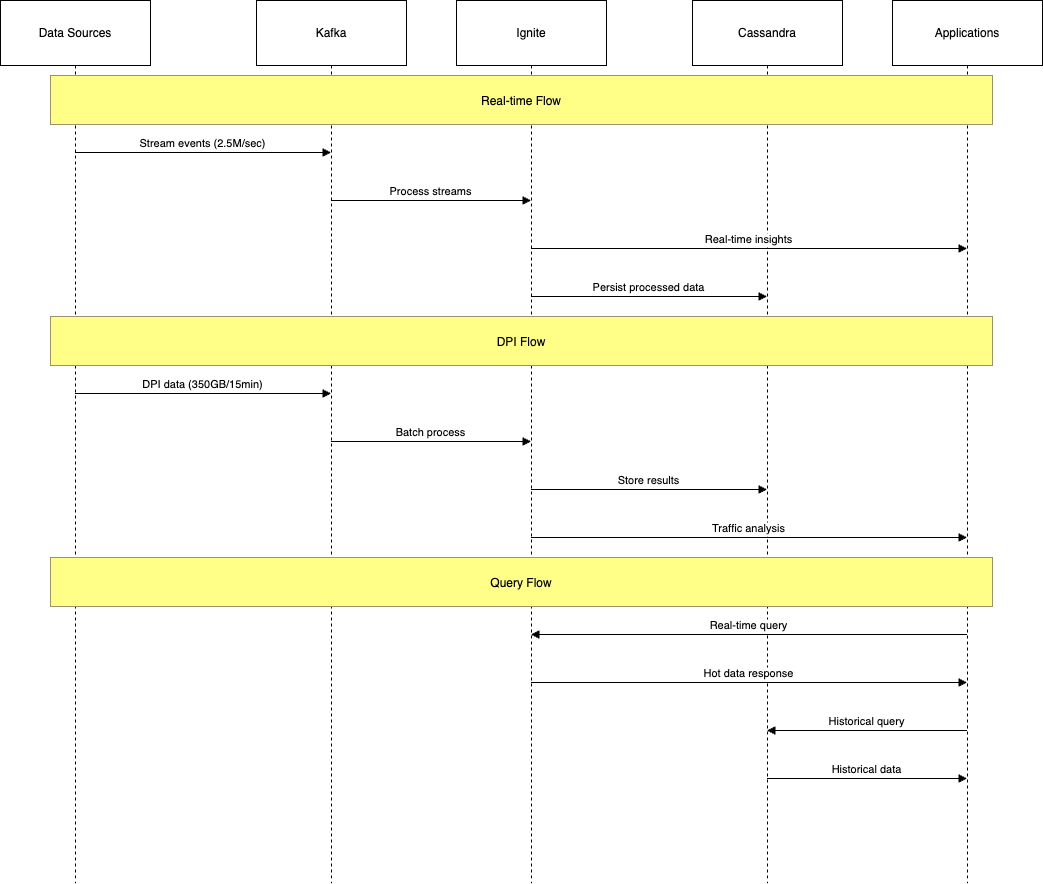
-
Data Ingestion
- Multiple collection points
- Protocol-specific handlers
- Load balancing
- Initial validation
-
Processing Pipeline
- Stream processing
- Real-time analytics
- State management
- Event correlation
-
Storage Strategy
- Hot data in memory
- Warm data on SSDs
- Cold data in object storage
- Automated tiering
-
Query Handling
- Real-time queries
- Historical queries
- Aggregation queries
- Analytics queries
Performance Characteristics
Latency Targets
- Real-time events: < 50ms
- DPI processing: < 5 minutes
- Query response: < 100ms
- State updates: < 10ms
Throughput Achievements
- Event processing: 2.5M/second
- DPI processing: 350GB/15min
- Storage writes: 100K/second
- Query processing: 10K/second
Looking Ahead
In the upcoming parts of this series, we’ll dive deep into:
- Data partitioning strategies
- Memory management techniques
- Stream processing optimization
- DPI data processing
- Failure handling mechanisms
- Performance monitoring
- Optimization strategies
Each part will include detailed technical implementations, code examples, and real-world learnings from building and operating this system at scale.
Stay tuned for Part 2, where we’ll explore our data partitioning strategy and how we managed the massive data flow through the system.